


หมากรุก ตอนที่ 4
นิทานเรื่องจริง เรื่อง “หมากรุก”
ตอน 4
หลังจากสับคอต่อ คู่แข่งของสงครามโลกครั้งที่ 2 คือ เยอรมัน กับญี่ปุ่น จนคอตั้งหัวตรงบนบ่าไม่เป็น ไปเรียบร้อยในปี ค.ศ.1945 ตลอดเวลา 70 ปี หลังจากนั้น อเมริกาก็คร่ำเคร่ง อยู่กับการวางกองกำลังหลายชั้น สลับซับซ้อน เพื่อเป็นการปิดล้อมรัสเซียกับจีน รายหนึ่งอยู่ heartland กล่องดวงใจของยูเรเซีย อีกราย แม้จะอยู่นอกกล่อง แต่ก็อยู่บนผืนแผ่นดินเดียวกัน ไม่ใช่ห่างคนละซีกโลกเหมือนตัว เกิดเขาเอื้อมมาคว้าเอากล่องดวงใจไปครองได้ก่อน อเมริกาจะทำยังไง คิดแล้วก็เสียวจนปวดท้อง อย่างนี้ มันก็ต้องวางแผนซ่อนกันหน่อย
อเมริกาเห็นตัวอย่าง จากการเป็นผู้นำโลกของจักรภพอังกฤษ ที่(เคย) เป็นนักล่าอาณานิคมหมายเลขหนึ่ง มีจุดโหว่แยะ อเมริกาจึงสร้างเสื้อคลุมประชาธิปไตย มาใส่หลอกชาวบ้าน เพื่อปิดจุดโหว่ ทำเป็นปิด แต่ ยุทธศาสตร์ของจริงอเมริกา ก็ไม่ได้ต่างกับของอังกฤษ มันเป็นการสร้างจักรวรรดิอเมริกา ขึ้นมาแทนที่จักรภพอังกฤษ เพื่อมาเป็นมหาอำนาจหมายเลขหนึ่งของโลก ที่มีเป้าหมายที่จะไม่ให้รัสเซีย หรือจีน เข้ามาชิงตำแหน่งมหาอำนาจหมายเลขหนึ่งนี้ไปอย่างเด็ดขาด
อันที่จริงในปี ค.ศ.1943 สองปีก่อนที่สงครามโลกครั้งที่ 2 จะสิ้นสุดลง ครูแมคซึ่งแก่มากแล้ว แต่ยังมองโลกกลมเหมือนเดิม ได้เขียนบทความชื่อ ” The Round World and the Winning of Peace” โลกกลมกับชัยชนะของสันติภาพ ลงในนิตยสาร Foreign Affairs ของถังขยะความคิด CFR ที่ใหญ่คับโลก เตือนสติอเมริกา ไว้ว่า
…..”dream of a global air power” would not change geopolitical basics … If the Soviet Union emerges from this war as conqueror of Germany .. she must rank as the greatest land power on the globe… controlling the greatest natural fortress on earth”
…..ความฝันของการเป็นเจ้าแห่งเวหา ก็ใช่ว่าจะเปลี่ยนรากฐานของภูมิศาสตร์การเมืองได้ …..ถ้าโซเวียต เกิดเป็นผู้ชนะเยอรมันในสงครามครั้งนี้ โซเวียตจะกลายเป็นมหาอำนาจใหญ่ยิ่งแห่งภาคพื้นดินของโลก …และเป็นผู้ครอบครองดินแดน ที่มีป้อมปราการทางธรรมชาติ ที่ยิ่งใหญ่ที่สุดในโลกใบนี้….
ดูเหมือนบทความของครูแมค จะกลายเป็นตัวเร่ง ให้อเมริกาออกคำสั่งประหารสหภาพโซเวียต
และเมื่อสงครามโลกครั้งที่ 2 สิ้นสุดลง อเมริกาก็ประกาศศักราชแห่งเสรีภาพ Pax Americana ด้วยการเริ่มรายการปิดล้อมสหภาพโซเวียต ที่อยู่ฝ่ายเดียวกันในตอนทำสงครามโลก โดยการใช้อำนาจทางกองทัพเรือของตน รายล้อมรอบยูเรเซียไว้จนหมดสิ้น เสื้อคลุมเสรีภาพทำงานหนักมาก
– กองทัพเรือที่ 6 ตั้งฐานไว้ที่เมืองเนเปิลส์ ตั้งแต่ปี ค.ศ.1946 เพื่อควบคุมมหาสมุทรแอตแลนติก และทะเลเมดิเตอร์เรเนียน
– กองทัพเรือที่ 7 ตั้งฐานไว้ที่อ่าวซูบิคของฟิลิปปีนส์ ตั้งแต่ปี ค.ศ.1947 เพื่อควบคุมแปซิฟิคด้านตะวันตก
– กองทัพเรือที่ 5 ตั้งฐานไว้ที่บาห์เรน ที่อ่าวเปอร์เซีย ตั้งแต่ปี ค.ศ.1995
ทั้ง heartland และ rimland อยู่ในวงล้อมเรียบร้อย
ต่อจากนั้น อเมริกาก็ใช้อำนาจทางด้านการทูต เข้ามาเสริมการปิดล้อมทางทหารอีกชั้น ด้วยการลากและจูงลูกหาบ มาเป็นสมาชิกองค์กรนาโต้ The North Atlantic Treaty Organization ในปี ค.ศ.1949
ยังไม่พอใช่ไหม เสื้อคลุมเสรีภาพยังครอบคลุมไม่พอ ….. อเมริกาจึงตั้ง The Middle East Treaty Organization ในปี ค.ศ.1955
อ้าว แล้วแถวเอเซียล่ะ….ไม่รอดหรอกน่า…. แล้ว The Southeast Asia Treaty Organization หรือที่เราเรียกกันว่า ซีโต้ ก็เกิดขึ้นในปี ค.ศ.1954 และ US -Japan Securty Treaty ในปี ค.ศ.1951 ก็ตามมา
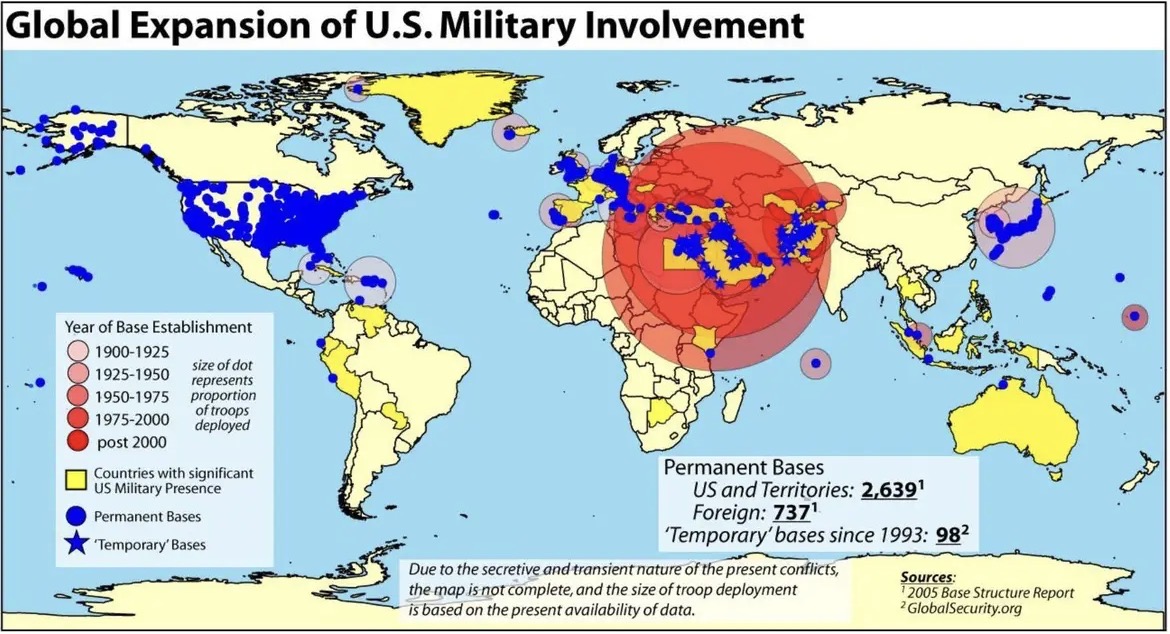
ถึงปี ค.ศ.1955 อเมริกาตั้งเครือข่ายฐานทัพไว้เกือบทั่วโลก ประมาณ 450 ฐานทัพ ใน 36 ประเทศ เพื่อเอาไว้ปิดล้อมรัสเซียและจีน เป็นยุทธศาสตร์ ที่เหมือนบังเอิญสร้างจากทฤษฏีครูแมค ทั้งปิดทั้งล้อม พวกที่อยู่บนแผ่นดิน โดยพวกที่อยู่บนเกาะ…
สงครามเย็นเลิกในปี ค.ศ.1991 แต่การปิดล้อมรัสเซียกับจีน กลับเพิ่มมากขึ้น ฐานทัพอเมริกันเพิ่มเป็นกว่า 700 แห่ง มีเครื่องบินรบประมาณ 1,763 เครื่อง ประจำการพร้อมรบ มีอาวุธนิวเคลียร์และระบบต้านการโจมตีทางจรวดกว่า 1,000 ชุด มีเรือรบประมาณ 600 ลำ รวมทั้งหัวรบนิวเคลียร์ 15 ลูก ทั้งหมดเชื่อมโยงกันด้วยระบบการสื่อสารผ่านดาวเทียม
อ่าวเปอร์เซีย ถูกเลือกให้เป็นจุดศูนย์กลาง ของยุทธศาสตร์ของอเมริกาในการปิดล้อม World Island และบริเวณอ่าวเปอร์เซีย จึงถูกอเมริกาเข้าไปแทรกแซงมากที่สุด ทั้งทางตรง ทางอ้อม เปิดเผย และแปลงตัว หรือ พรางตัว
การปฏิวัติในอิหร่านเพื่อเปลี่ยนตัวผู้ปกครอง การโค่นล้มซัดดัมแห่งอิรัค การสร้างนักรบมูจาฮิดีนของอาฟกานิสถาน ทั้งหมดล้วนเป็นแผนตามยุทธศาสตร์ของอเมริกา ที่ต้องการสร้างความสั่นคลอนให้กับโซเวียตในทางตรง และทางอ้อมทั้งสิ้น ถ้าเอาแผนที่มาดูบริเวณที่ตั้งของประเทศเหล่านี้ คงจะเข้าใจการเดินหมากของอเมริกามากขึ้น
ขนาดเจอแผนตามยุทธศาสตร์ แบบจัดหนักขนาดนี้ แต่โซเวียตก็ยังไม่ตายสนิทสมใจอเมริกา ไอ้คุณแสบเบรซินสกี้ ที่ปรึกษาของพณฯ ท่านถั่ว จิมมี่ คาร์เตอร์ จึงเสนอให้ใช้ปฏิบัติการ Operation Cyclone ในช่วงปี ค.ศ.1980 กว่าๆ ที่ใช้งบสูงถึงปีละประมาณ 500 ล้านเหรียญ เพื่อจัดตั้งกองทัพมุสลิม เอาไว้โจมตีเอเซียกลาง และจัดส่งอิสลามหัวรุนแรงเข้าไปในโซเวียต heartland
ขณะเดียวกัน อเมริกาก็พยายามสร้างความแตกแยกให้เกิดขึ้นกับกองทัพของอาฟกานิสถาน ที่เคยเป็นเพื่อนกับโซเวียต และค่อยๆแซะให้ยุโรปตะวันออก แยกตัวมาจากการเกาะกลุ่มกับโซเวียต
เมื่อมีผู้ถามไอ้คุณแสบ เบรซินสกี้ ภายหลังว่า คิดยังไงถึงสร้างกองกำลังมุสลิม ที่ภายหลังก็กลายเป็นปัญหากับอเมริกาเอง ไอ้คุณแสบย้อนถามกลับว่า อะไรสำคัญกว่าในประวัติศาสตร์ของโลก พวกตาลีบัน หรือการล่มสลายของสหภาพโซเวียต?
คำตอบนี้ น่าจะทำให้เราเริ่มรู้จัก “ยุทธศาสตร์” ของอเมริกา….
แม้อเมริกาจะมีชัยชนะจากสงครามเย็น โซเวียตล่มสลายตามแผน แต่ชัยชนะนั้นก็ไม่สามารถเปลี่ยนสภาพทางภูมิศาสตร์ของ World Island ได้
หลังจากทุบกำแพงเบอร์ลินทิ้งลง ในปี ค.ศ.1989 อเมริกาก็รีบร่างนโยบายต่างประเทศขึ้นมาใหม่อีกอย่างรวดเร็ว เพื่อเป็นปฏิบัติการยุค “หลัง” สงครามเย็น มันก็คือการปิดล้อมต่อนั่นแหละ แต่มาในรูปแบบใหม่ ด้วยการยึดอ่าวเปอร์เซียเป็นที่มั่น โดยใช้การบุกคูเวตของซัดดัมเป็นข้ออ้าง…
ปี ค.ศ.2003 เมื่ออเมริกาบุกอิรัค Paul Kennedy นักประวัติศาสตร์ชื่อดังของชาวเกาะใหญ่เท่าปลายนิ้วก้อยฯ ที่เห็นพ้องกับทฤษฏีของครูแมค ได้เขียนในสื่ออังกฤษ The Guardian ว่า … ขณะนี้ ทหารจำนวนหลายแสนของอเมริกา กำลังอยู่ที่ชายขอบ rimland ของยูเรเซีย ดูเหมือนว่า อเมริกากำลังเดินตามคำเตือนของครูแมค โดยมุ่งมั่นที่จะควบคุม ” จุดสำคัญทางภูมิศาสตร์ ที่สร้างประวัติศาสตร์ ” the geographical pivot of history
เวลาผ่านไป อเมริกาก็เพิ่มการปิดล้อม เหนือชั้นขึ้นไปอีก แค่เอาทหารไปประจำการ boots on the ground มันยังล้อมไม่ถึงใจ ครอบคลุมไม่ได้หมด อเมริกาจึงใช้ ลูกตา และอาวุธลอยฟ้า ที่เรียกว่า “โดรน” drone เพิ่มเข้ามา
ปี ค.ศ.2011 กองทัพอากาศอเมริกันร่วมงานกับซีไอเอ สร้างฐานโดรนขึ้นมารอบ World Island ตั้งแต่ ซินโยเนลลาในซิซีลี ไปจนถึง อินเซอลิกที่ตุรกี ลงมาที่จิบูติ ตรงทะเลแดง ขึ้นไปที่กาตาร์ อาบูดาบี ที่อ่าวเปอร์เซีย ออกมาต่อที่หมู่เกาะซีเชลล์ ในมหาสมุทรอินเดีย จาลาละบัด โคสต์ กันดาหาร์ ชินดัน ในอาฟกานิสถาน ลงมาแปซิฟิก แซมบิโอก้า ในฟิลิปปินส์ รวมทั้งที่สนามบินแอนเดอร์สัน ที่เกาะกวม โฮ๊ย… ไล่อ่านชื่อตามแผนที่เสียลูกตาแทบหลุด
เพนตากอนจ่ายเงิน สำหรับโครนลอยฟ้าไปแค่ 1 หมื่นล้านเหรียญ เพื่อสร้างฝูงโดรนตาเหยี่ยว Global Hawk 99 ตัว ที่ติดตั้งกล้องสำรวจพื้นที่รัศมีหลายร้อยไมล์ มีเครื่องอีเลคโทรนิคที่พร้อมสื่อสารเป็นเวลานานติดต่อกันถึง 35 ชั่วโมง และในระยะทางไม่น้อยกว่า 8,700 ไมล์
แค่เขียนเล่าก็เหนื่อยแล้วครับ ไม่รู้ว่ามันเป็นบ้าอะไร ถ้ามันบ้าทฤษฏีครูแมคนัก ทำไมมันไม่ได้คิดต่อจากที่ครูแมคพูดเลยหรือ … แม้แต่การเป็นเจ้าเวหา ก็ใช่ว่าจะเอาชนะรากฐานของภูมิศาสตร์การเมืองได้ ….
สวัสดีครับ
คนเล่านิทาน
25 ธ.ค. 2558
นิทานเรื่องจริง เรื่อง “หมากรุก”
ตอน 4
หลังจากสับคอต่อ คู่แข่งของสงครามโลกครั้งที่ 2 คือ เยอรมัน กับญี่ปุ่น จนคอตั้งหัวตรงบนบ่าไม่เป็น ไปเรียบร้อยในปี ค.ศ.1945 ตลอดเวลา 70 ปี หลังจากนั้น อเมริกาก็คร่ำเคร่ง อยู่กับการวางกองกำลังหลายชั้น สลับซับซ้อน เพื่อเป็นการปิดล้อมรัสเซียกับจีน รายหนึ่งอยู่ heartland กล่องดวงใจของยูเรเซีย อีกราย แม้จะอยู่นอกกล่อง แต่ก็อยู่บนผืนแผ่นดินเดียวกัน ไม่ใช่ห่างคนละซีกโลกเหมือนตัว เกิดเขาเอื้อมมาคว้าเอากล่องดวงใจไปครองได้ก่อน อเมริกาจะทำยังไง คิดแล้วก็เสียวจนปวดท้อง อย่างนี้ มันก็ต้องวางแผนซ่อนกันหน่อย
อเมริกาเห็นตัวอย่าง จากการเป็นผู้นำโลกของจักรภพอังกฤษ ที่(เคย) เป็นนักล่าอาณานิคมหมายเลขหนึ่ง มีจุดโหว่แยะ อเมริกาจึงสร้างเสื้อคลุมประชาธิปไตย มาใส่หลอกชาวบ้าน เพื่อปิดจุดโหว่ ทำเป็นปิด แต่ ยุทธศาสตร์ของจริงอเมริกา ก็ไม่ได้ต่างกับของอังกฤษ มันเป็นการสร้างจักรวรรดิอเมริกา ขึ้นมาแทนที่จักรภพอังกฤษ เพื่อมาเป็นมหาอำนาจหมายเลขหนึ่งของโลก ที่มีเป้าหมายที่จะไม่ให้รัสเซีย หรือจีน เข้ามาชิงตำแหน่งมหาอำนาจหมายเลขหนึ่งนี้ไปอย่างเด็ดขาด
อันที่จริงในปี ค.ศ.1943 สองปีก่อนที่สงครามโลกครั้งที่ 2 จะสิ้นสุดลง ครูแมคซึ่งแก่มากแล้ว แต่ยังมองโลกกลมเหมือนเดิม ได้เขียนบทความชื่อ ” The Round World and the Winning of Peace” โลกกลมกับชัยชนะของสันติภาพ ลงในนิตยสาร Foreign Affairs ของถังขยะความคิด CFR ที่ใหญ่คับโลก เตือนสติอเมริกา ไว้ว่า
…..”dream of a global air power” would not change geopolitical basics … If the Soviet Union emerges from this war as conqueror of Germany .. she must rank as the greatest land power on the globe… controlling the greatest natural fortress on earth”
…..ความฝันของการเป็นเจ้าแห่งเวหา ก็ใช่ว่าจะเปลี่ยนรากฐานของภูมิศาสตร์การเมืองได้ …..ถ้าโซเวียต เกิดเป็นผู้ชนะเยอรมันในสงครามครั้งนี้ โซเวียตจะกลายเป็นมหาอำนาจใหญ่ยิ่งแห่งภาคพื้นดินของโลก …และเป็นผู้ครอบครองดินแดน ที่มีป้อมปราการทางธรรมชาติ ที่ยิ่งใหญ่ที่สุดในโลกใบนี้….
ดูเหมือนบทความของครูแมค จะกลายเป็นตัวเร่ง ให้อเมริกาออกคำสั่งประหารสหภาพโซเวียต
และเมื่อสงครามโลกครั้งที่ 2 สิ้นสุดลง อเมริกาก็ประกาศศักราชแห่งเสรีภาพ Pax Americana ด้วยการเริ่มรายการปิดล้อมสหภาพโซเวียต ที่อยู่ฝ่ายเดียวกันในตอนทำสงครามโลก โดยการใช้อำนาจทางกองทัพเรือของตน รายล้อมรอบยูเรเซียไว้จนหมดสิ้น เสื้อคลุมเสรีภาพทำงานหนักมาก
– กองทัพเรือที่ 6 ตั้งฐานไว้ที่เมืองเนเปิลส์ ตั้งแต่ปี ค.ศ.1946 เพื่อควบคุมมหาสมุทรแอตแลนติก และทะเลเมดิเตอร์เรเนียน
– กองทัพเรือที่ 7 ตั้งฐานไว้ที่อ่าวซูบิคของฟิลิปปีนส์ ตั้งแต่ปี ค.ศ.1947 เพื่อควบคุมแปซิฟิคด้านตะวันตก
– กองทัพเรือที่ 5 ตั้งฐานไว้ที่บาห์เรน ที่อ่าวเปอร์เซีย ตั้งแต่ปี ค.ศ.1995
ทั้ง heartland และ rimland อยู่ในวงล้อมเรียบร้อย
ต่อจากนั้น อเมริกาก็ใช้อำนาจทางด้านการทูต เข้ามาเสริมการปิดล้อมทางทหารอีกชั้น ด้วยการลากและจูงลูกหาบ มาเป็นสมาชิกองค์กรนาโต้ The North Atlantic Treaty Organization ในปี ค.ศ.1949
ยังไม่พอใช่ไหม เสื้อคลุมเสรีภาพยังครอบคลุมไม่พอ ….. อเมริกาจึงตั้ง The Middle East Treaty Organization ในปี ค.ศ.1955
อ้าว แล้วแถวเอเซียล่ะ….ไม่รอดหรอกน่า…. แล้ว The Southeast Asia Treaty Organization หรือที่เราเรียกกันว่า ซีโต้ ก็เกิดขึ้นในปี ค.ศ.1954 และ US -Japan Securty Treaty ในปี ค.ศ.1951 ก็ตามมา
ถึงปี ค.ศ.1955 อเมริกาตั้งเครือข่ายฐานทัพไว้เกือบทั่วโลก ประมาณ 450 ฐานทัพ ใน 36 ประเทศ เพื่อเอาไว้ปิดล้อมรัสเซียและจีน เป็นยุทธศาสตร์ ที่เหมือนบังเอิญสร้างจากทฤษฏีครูแมค ทั้งปิดทั้งล้อม พวกที่อยู่บนแผ่นดิน โดยพวกที่อยู่บนเกาะ…
สงครามเย็นเลิกในปี ค.ศ.1991 แต่การปิดล้อมรัสเซียกับจีน กลับเพิ่มมากขึ้น ฐานทัพอเมริกันเพิ่มเป็นกว่า 700 แห่ง มีเครื่องบินรบประมาณ 1,763 เครื่อง ประจำการพร้อมรบ มีอาวุธนิวเคลียร์และระบบต้านการโจมตีทางจรวดกว่า 1,000 ชุด มีเรือรบประมาณ 600 ลำ รวมทั้งหัวรบนิวเคลียร์ 15 ลูก ทั้งหมดเชื่อมโยงกันด้วยระบบการสื่อสารผ่านดาวเทียม
อ่าวเปอร์เซีย ถูกเลือกให้เป็นจุดศูนย์กลาง ของยุทธศาสตร์ของอเมริกาในการปิดล้อม World Island และบริเวณอ่าวเปอร์เซีย จึงถูกอเมริกาเข้าไปแทรกแซงมากที่สุด ทั้งทางตรง ทางอ้อม เปิดเผย และแปลงตัว หรือ พรางตัว
การปฏิวัติในอิหร่านเพื่อเปลี่ยนตัวผู้ปกครอง การโค่นล้มซัดดัมแห่งอิรัค การสร้างนักรบมูจาฮิดีนของอาฟกานิสถาน ทั้งหมดล้วนเป็นแผนตามยุทธศาสตร์ของอเมริกา ที่ต้องการสร้างความสั่นคลอนให้กับโซเวียตในทางตรง และทางอ้อมทั้งสิ้น ถ้าเอาแผนที่มาดูบริเวณที่ตั้งของประเทศเหล่านี้ คงจะเข้าใจการเดินหมากของอเมริกามากขึ้น
ขนาดเจอแผนตามยุทธศาสตร์ แบบจัดหนักขนาดนี้ แต่โซเวียตก็ยังไม่ตายสนิทสมใจอเมริกา ไอ้คุณแสบเบรซินสกี้ ที่ปรึกษาของพณฯ ท่านถั่ว จิมมี่ คาร์เตอร์ จึงเสนอให้ใช้ปฏิบัติการ Operation Cyclone ในช่วงปี ค.ศ.1980 กว่าๆ ที่ใช้งบสูงถึงปีละประมาณ 500 ล้านเหรียญ เพื่อจัดตั้งกองทัพมุสลิม เอาไว้โจมตีเอเซียกลาง และจัดส่งอิสลามหัวรุนแรงเข้าไปในโซเวียต heartland
ขณะเดียวกัน อเมริกาก็พยายามสร้างความแตกแยกให้เกิดขึ้นกับกองทัพของอาฟกานิสถาน ที่เคยเป็นเพื่อนกับโซเวียต และค่อยๆแซะให้ยุโรปตะวันออก แยกตัวมาจากการเกาะกลุ่มกับโซเวียต
เมื่อมีผู้ถามไอ้คุณแสบ เบรซินสกี้ ภายหลังว่า คิดยังไงถึงสร้างกองกำลังมุสลิม ที่ภายหลังก็กลายเป็นปัญหากับอเมริกาเอง ไอ้คุณแสบย้อนถามกลับว่า อะไรสำคัญกว่าในประวัติศาสตร์ของโลก พวกตาลีบัน หรือการล่มสลายของสหภาพโซเวียต?
คำตอบนี้ น่าจะทำให้เราเริ่มรู้จัก “ยุทธศาสตร์” ของอเมริกา….
แม้อเมริกาจะมีชัยชนะจากสงครามเย็น โซเวียตล่มสลายตามแผน แต่ชัยชนะนั้นก็ไม่สามารถเปลี่ยนสภาพทางภูมิศาสตร์ของ World Island ได้
หลังจากทุบกำแพงเบอร์ลินทิ้งลง ในปี ค.ศ.1989 อเมริกาก็รีบร่างนโยบายต่างประเทศขึ้นมาใหม่อีกอย่างรวดเร็ว เพื่อเป็นปฏิบัติการยุค “หลัง” สงครามเย็น มันก็คือการปิดล้อมต่อนั่นแหละ แต่มาในรูปแบบใหม่ ด้วยการยึดอ่าวเปอร์เซียเป็นที่มั่น โดยใช้การบุกคูเวตของซัดดัมเป็นข้ออ้าง…
ปี ค.ศ.2003 เมื่ออเมริกาบุกอิรัค Paul Kennedy นักประวัติศาสตร์ชื่อดังของชาวเกาะใหญ่เท่าปลายนิ้วก้อยฯ ที่เห็นพ้องกับทฤษฏีของครูแมค ได้เขียนในสื่ออังกฤษ The Guardian ว่า … ขณะนี้ ทหารจำนวนหลายแสนของอเมริกา กำลังอยู่ที่ชายขอบ rimland ของยูเรเซีย ดูเหมือนว่า อเมริกากำลังเดินตามคำเตือนของครูแมค โดยมุ่งมั่นที่จะควบคุม ” จุดสำคัญทางภูมิศาสตร์ ที่สร้างประวัติศาสตร์ ” the geographical pivot of history
เวลาผ่านไป อเมริกาก็เพิ่มการปิดล้อม เหนือชั้นขึ้นไปอีก แค่เอาทหารไปประจำการ boots on the ground มันยังล้อมไม่ถึงใจ ครอบคลุมไม่ได้หมด อเมริกาจึงใช้ ลูกตา และอาวุธลอยฟ้า ที่เรียกว่า “โดรน” drone เพิ่มเข้ามา
ปี ค.ศ.2011 กองทัพอากาศอเมริกันร่วมงานกับซีไอเอ สร้างฐานโดรนขึ้นมารอบ World Island ตั้งแต่ ซินโยเนลลาในซิซีลี ไปจนถึง อินเซอลิกที่ตุรกี ลงมาที่จิบูติ ตรงทะเลแดง ขึ้นไปที่กาตาร์ อาบูดาบี ที่อ่าวเปอร์เซีย ออกมาต่อที่หมู่เกาะซีเชลล์ ในมหาสมุทรอินเดีย จาลาละบัด โคสต์ กันดาหาร์ ชินดัน ในอาฟกานิสถาน ลงมาแปซิฟิก แซมบิโอก้า ในฟิลิปปินส์ รวมทั้งที่สนามบินแอนเดอร์สัน ที่เกาะกวม โฮ๊ย… ไล่อ่านชื่อตามแผนที่เสียลูกตาแทบหลุด
เพนตากอนจ่ายเงิน สำหรับโครนลอยฟ้าไปแค่ 1 หมื่นล้านเหรียญ เพื่อสร้างฝูงโดรนตาเหยี่ยว Global Hawk 99 ตัว ที่ติดตั้งกล้องสำรวจพื้นที่รัศมีหลายร้อยไมล์ มีเครื่องอีเลคโทรนิคที่พร้อมสื่อสารเป็นเวลานานติดต่อกันถึง 35 ชั่วโมง และในระยะทางไม่น้อยกว่า 8,700 ไมล์
แค่เขียนเล่าก็เหนื่อยแล้วครับ ไม่รู้ว่ามันเป็นบ้าอะไร ถ้ามันบ้าทฤษฏีครูแมคนัก ทำไมมันไม่ได้คิดต่อจากที่ครูแมคพูดเลยหรือ … แม้แต่การเป็นเจ้าเวหา ก็ใช่ว่าจะเอาชนะรากฐานของภูมิศาสตร์การเมืองได้ ….
สวัสดีครับ
คนเล่านิทาน
25 ธ.ค. 2558
หมากรุก ตอนที่ 4
นิทานเรื่องจริง เรื่อง “หมากรุก”
ตอน 4
หลังจากสับคอต่อ คู่แข่งของสงครามโลกครั้งที่ 2 คือ เยอรมัน กับญี่ปุ่น จนคอตั้งหัวตรงบนบ่าไม่เป็น ไปเรียบร้อยในปี ค.ศ.1945 ตลอดเวลา 70 ปี หลังจากนั้น อเมริกาก็คร่ำเคร่ง อยู่กับการวางกองกำลังหลายชั้น สลับซับซ้อน เพื่อเป็นการปิดล้อมรัสเซียกับจีน รายหนึ่งอยู่ heartland กล่องดวงใจของยูเรเซีย อีกราย แม้จะอยู่นอกกล่อง แต่ก็อยู่บนผืนแผ่นดินเดียวกัน ไม่ใช่ห่างคนละซีกโลกเหมือนตัว เกิดเขาเอื้อมมาคว้าเอากล่องดวงใจไปครองได้ก่อน อเมริกาจะทำยังไง คิดแล้วก็เสียวจนปวดท้อง อย่างนี้ มันก็ต้องวางแผนซ่อนกันหน่อย
อเมริกาเห็นตัวอย่าง จากการเป็นผู้นำโลกของจักรภพอังกฤษ ที่(เคย) เป็นนักล่าอาณานิคมหมายเลขหนึ่ง มีจุดโหว่แยะ อเมริกาจึงสร้างเสื้อคลุมประชาธิปไตย มาใส่หลอกชาวบ้าน เพื่อปิดจุดโหว่ ทำเป็นปิด แต่ ยุทธศาสตร์ของจริงอเมริกา ก็ไม่ได้ต่างกับของอังกฤษ มันเป็นการสร้างจักรวรรดิอเมริกา ขึ้นมาแทนที่จักรภพอังกฤษ เพื่อมาเป็นมหาอำนาจหมายเลขหนึ่งของโลก ที่มีเป้าหมายที่จะไม่ให้รัสเซีย หรือจีน เข้ามาชิงตำแหน่งมหาอำนาจหมายเลขหนึ่งนี้ไปอย่างเด็ดขาด
อันที่จริงในปี ค.ศ.1943 สองปีก่อนที่สงครามโลกครั้งที่ 2 จะสิ้นสุดลง ครูแมคซึ่งแก่มากแล้ว แต่ยังมองโลกกลมเหมือนเดิม ได้เขียนบทความชื่อ ” The Round World and the Winning of Peace” โลกกลมกับชัยชนะของสันติภาพ ลงในนิตยสาร Foreign Affairs ของถังขยะความคิด CFR ที่ใหญ่คับโลก เตือนสติอเมริกา ไว้ว่า
…..”dream of a global air power” would not change geopolitical basics … If the Soviet Union emerges from this war as conqueror of Germany .. she must rank as the greatest land power on the globe… controlling the greatest natural fortress on earth”
…..ความฝันของการเป็นเจ้าแห่งเวหา ก็ใช่ว่าจะเปลี่ยนรากฐานของภูมิศาสตร์การเมืองได้ …..ถ้าโซเวียต เกิดเป็นผู้ชนะเยอรมันในสงครามครั้งนี้ โซเวียตจะกลายเป็นมหาอำนาจใหญ่ยิ่งแห่งภาคพื้นดินของโลก …และเป็นผู้ครอบครองดินแดน ที่มีป้อมปราการทางธรรมชาติ ที่ยิ่งใหญ่ที่สุดในโลกใบนี้….
ดูเหมือนบทความของครูแมค จะกลายเป็นตัวเร่ง ให้อเมริกาออกคำสั่งประหารสหภาพโซเวียต
และเมื่อสงครามโลกครั้งที่ 2 สิ้นสุดลง อเมริกาก็ประกาศศักราชแห่งเสรีภาพ Pax Americana ด้วยการเริ่มรายการปิดล้อมสหภาพโซเวียต ที่อยู่ฝ่ายเดียวกันในตอนทำสงครามโลก โดยการใช้อำนาจทางกองทัพเรือของตน รายล้อมรอบยูเรเซียไว้จนหมดสิ้น เสื้อคลุมเสรีภาพทำงานหนักมาก
– กองทัพเรือที่ 6 ตั้งฐานไว้ที่เมืองเนเปิลส์ ตั้งแต่ปี ค.ศ.1946 เพื่อควบคุมมหาสมุทรแอตแลนติก และทะเลเมดิเตอร์เรเนียน
– กองทัพเรือที่ 7 ตั้งฐานไว้ที่อ่าวซูบิคของฟิลิปปีนส์ ตั้งแต่ปี ค.ศ.1947 เพื่อควบคุมแปซิฟิคด้านตะวันตก
– กองทัพเรือที่ 5 ตั้งฐานไว้ที่บาห์เรน ที่อ่าวเปอร์เซีย ตั้งแต่ปี ค.ศ.1995
ทั้ง heartland และ rimland อยู่ในวงล้อมเรียบร้อย
ต่อจากนั้น อเมริกาก็ใช้อำนาจทางด้านการทูต เข้ามาเสริมการปิดล้อมทางทหารอีกชั้น ด้วยการลากและจูงลูกหาบ มาเป็นสมาชิกองค์กรนาโต้ The North Atlantic Treaty Organization ในปี ค.ศ.1949
ยังไม่พอใช่ไหม เสื้อคลุมเสรีภาพยังครอบคลุมไม่พอ ….. อเมริกาจึงตั้ง The Middle East Treaty Organization ในปี ค.ศ.1955
อ้าว แล้วแถวเอเซียล่ะ….ไม่รอดหรอกน่า…. แล้ว The Southeast Asia Treaty Organization หรือที่เราเรียกกันว่า ซีโต้ ก็เกิดขึ้นในปี ค.ศ.1954 และ US -Japan Securty Treaty ในปี ค.ศ.1951 ก็ตามมา
ถึงปี ค.ศ.1955 อเมริกาตั้งเครือข่ายฐานทัพไว้เกือบทั่วโลก ประมาณ 450 ฐานทัพ ใน 36 ประเทศ เพื่อเอาไว้ปิดล้อมรัสเซียและจีน เป็นยุทธศาสตร์ ที่เหมือนบังเอิญสร้างจากทฤษฏีครูแมค ทั้งปิดทั้งล้อม พวกที่อยู่บนแผ่นดิน โดยพวกที่อยู่บนเกาะ…
สงครามเย็นเลิกในปี ค.ศ.1991 แต่การปิดล้อมรัสเซียกับจีน กลับเพิ่มมากขึ้น ฐานทัพอเมริกันเพิ่มเป็นกว่า 700 แห่ง มีเครื่องบินรบประมาณ 1,763 เครื่อง ประจำการพร้อมรบ มีอาวุธนิวเคลียร์และระบบต้านการโจมตีทางจรวดกว่า 1,000 ชุด มีเรือรบประมาณ 600 ลำ รวมทั้งหัวรบนิวเคลียร์ 15 ลูก ทั้งหมดเชื่อมโยงกันด้วยระบบการสื่อสารผ่านดาวเทียม
อ่าวเปอร์เซีย ถูกเลือกให้เป็นจุดศูนย์กลาง ของยุทธศาสตร์ของอเมริกาในการปิดล้อม World Island และบริเวณอ่าวเปอร์เซีย จึงถูกอเมริกาเข้าไปแทรกแซงมากที่สุด ทั้งทางตรง ทางอ้อม เปิดเผย และแปลงตัว หรือ พรางตัว
การปฏิวัติในอิหร่านเพื่อเปลี่ยนตัวผู้ปกครอง การโค่นล้มซัดดัมแห่งอิรัค การสร้างนักรบมูจาฮิดีนของอาฟกานิสถาน ทั้งหมดล้วนเป็นแผนตามยุทธศาสตร์ของอเมริกา ที่ต้องการสร้างความสั่นคลอนให้กับโซเวียตในทางตรง และทางอ้อมทั้งสิ้น ถ้าเอาแผนที่มาดูบริเวณที่ตั้งของประเทศเหล่านี้ คงจะเข้าใจการเดินหมากของอเมริกามากขึ้น
ขนาดเจอแผนตามยุทธศาสตร์ แบบจัดหนักขนาดนี้ แต่โซเวียตก็ยังไม่ตายสนิทสมใจอเมริกา ไอ้คุณแสบเบรซินสกี้ ที่ปรึกษาของพณฯ ท่านถั่ว จิมมี่ คาร์เตอร์ จึงเสนอให้ใช้ปฏิบัติการ Operation Cyclone ในช่วงปี ค.ศ.1980 กว่าๆ ที่ใช้งบสูงถึงปีละประมาณ 500 ล้านเหรียญ เพื่อจัดตั้งกองทัพมุสลิม เอาไว้โจมตีเอเซียกลาง และจัดส่งอิสลามหัวรุนแรงเข้าไปในโซเวียต heartland
ขณะเดียวกัน อเมริกาก็พยายามสร้างความแตกแยกให้เกิดขึ้นกับกองทัพของอาฟกานิสถาน ที่เคยเป็นเพื่อนกับโซเวียต และค่อยๆแซะให้ยุโรปตะวันออก แยกตัวมาจากการเกาะกลุ่มกับโซเวียต
เมื่อมีผู้ถามไอ้คุณแสบ เบรซินสกี้ ภายหลังว่า คิดยังไงถึงสร้างกองกำลังมุสลิม ที่ภายหลังก็กลายเป็นปัญหากับอเมริกาเอง ไอ้คุณแสบย้อนถามกลับว่า อะไรสำคัญกว่าในประวัติศาสตร์ของโลก พวกตาลีบัน หรือการล่มสลายของสหภาพโซเวียต?
คำตอบนี้ น่าจะทำให้เราเริ่มรู้จัก “ยุทธศาสตร์” ของอเมริกา….
แม้อเมริกาจะมีชัยชนะจากสงครามเย็น โซเวียตล่มสลายตามแผน แต่ชัยชนะนั้นก็ไม่สามารถเปลี่ยนสภาพทางภูมิศาสตร์ของ World Island ได้
หลังจากทุบกำแพงเบอร์ลินทิ้งลง ในปี ค.ศ.1989 อเมริกาก็รีบร่างนโยบายต่างประเทศขึ้นมาใหม่อีกอย่างรวดเร็ว เพื่อเป็นปฏิบัติการยุค “หลัง” สงครามเย็น มันก็คือการปิดล้อมต่อนั่นแหละ แต่มาในรูปแบบใหม่ ด้วยการยึดอ่าวเปอร์เซียเป็นที่มั่น โดยใช้การบุกคูเวตของซัดดัมเป็นข้ออ้าง…
ปี ค.ศ.2003 เมื่ออเมริกาบุกอิรัค Paul Kennedy นักประวัติศาสตร์ชื่อดังของชาวเกาะใหญ่เท่าปลายนิ้วก้อยฯ ที่เห็นพ้องกับทฤษฏีของครูแมค ได้เขียนในสื่ออังกฤษ The Guardian ว่า … ขณะนี้ ทหารจำนวนหลายแสนของอเมริกา กำลังอยู่ที่ชายขอบ rimland ของยูเรเซีย ดูเหมือนว่า อเมริกากำลังเดินตามคำเตือนของครูแมค โดยมุ่งมั่นที่จะควบคุม ” จุดสำคัญทางภูมิศาสตร์ ที่สร้างประวัติศาสตร์ ” the geographical pivot of history
เวลาผ่านไป อเมริกาก็เพิ่มการปิดล้อม เหนือชั้นขึ้นไปอีก แค่เอาทหารไปประจำการ boots on the ground มันยังล้อมไม่ถึงใจ ครอบคลุมไม่ได้หมด อเมริกาจึงใช้ ลูกตา และอาวุธลอยฟ้า ที่เรียกว่า “โดรน” drone เพิ่มเข้ามา
ปี ค.ศ.2011 กองทัพอากาศอเมริกันร่วมงานกับซีไอเอ สร้างฐานโดรนขึ้นมารอบ World Island ตั้งแต่ ซินโยเนลลาในซิซีลี ไปจนถึง อินเซอลิกที่ตุรกี ลงมาที่จิบูติ ตรงทะเลแดง ขึ้นไปที่กาตาร์ อาบูดาบี ที่อ่าวเปอร์เซีย ออกมาต่อที่หมู่เกาะซีเชลล์ ในมหาสมุทรอินเดีย จาลาละบัด โคสต์ กันดาหาร์ ชินดัน ในอาฟกานิสถาน ลงมาแปซิฟิก แซมบิโอก้า ในฟิลิปปินส์ รวมทั้งที่สนามบินแอนเดอร์สัน ที่เกาะกวม โฮ๊ย… ไล่อ่านชื่อตามแผนที่เสียลูกตาแทบหลุด
เพนตากอนจ่ายเงิน สำหรับโครนลอยฟ้าไปแค่ 1 หมื่นล้านเหรียญ เพื่อสร้างฝูงโดรนตาเหยี่ยว Global Hawk 99 ตัว ที่ติดตั้งกล้องสำรวจพื้นที่รัศมีหลายร้อยไมล์ มีเครื่องอีเลคโทรนิคที่พร้อมสื่อสารเป็นเวลานานติดต่อกันถึง 35 ชั่วโมง และในระยะทางไม่น้อยกว่า 8,700 ไมล์
แค่เขียนเล่าก็เหนื่อยแล้วครับ ไม่รู้ว่ามันเป็นบ้าอะไร ถ้ามันบ้าทฤษฏีครูแมคนัก ทำไมมันไม่ได้คิดต่อจากที่ครูแมคพูดเลยหรือ … แม้แต่การเป็นเจ้าเวหา ก็ใช่ว่าจะเอาชนะรากฐานของภูมิศาสตร์การเมืองได้ ….
สวัสดีครับ
คนเล่านิทาน
25 ธ.ค. 2558
0 ความคิดเห็น
0 การแบ่งปัน
37 มุมมอง
0 รีวิว


