หมากรุก ตอนที่ 10
นิทานเรื่องจริง เรื่อง “หมากรุก”
ตอน 10 (จบ)
สรุปว่า ยุทธศาสตร์ของอเมริกาคือ ยุทธศาสตร์เพื่อการ “ครองโลกแต่ผู้เดียว” ที่ไม่เคยเปลี่ยนแปลงมาตลอด 70 ปีที่ผ่านมา
ส่วนยุทธศาสตร์ของรัสเซีย น่าจะเป็นยุทธศาสตร์ “รัสเซียแกร่งกล้า” ที่สร้างบ้านเมืองให้แข็งแกร่งขึ้นมาใหม่ได้ และพร้อมแล้วที่จะบอกกับอเมริกาว่า “พอได้แล้วนะ” อเมริกาไม่ได้เป็นผู้กำหนดชะตาของทุกประเทศในโลกนี้อีกแล้ว การก้าวเข้าไปในซีเรีย และตะวันออกกลางของรัสเซีย มันแปลได้อย่างนั้น
และยุทธศาสตร์ของจีน น่าจะเป็นยุทธศาสตร์ “จีนยิ่งใหญ่” หรือประเภทมังกรทะยานฟ้า เรื่องปิดล้อมจีนจบแล้ว อย่าได้คิดเชียวว่า จะมีใครมาปิด มาล้อมจีนได้อีก ไม่ว่าทางด้านเศรษฐกิจ หรือกำลังทหาร ไม่มีทางแล้ว
และตามยุทธศาสตร์ของทั้ง 3 ผู้ยิ่งใหญ่ อย่างน้อยต้องมีองค์ประกอบพื้นฐานเช่นเดียวกัน 3 เรื่อง เพื่อจะเดินหน้าตามแผนของตัวในช่วง 20 ปีที่ผ่านมา คือ
– มีอาวุธที่สุดยอด
– มีกองกำลังที่ยิ่งใหญ่
– ได้ครอบครองแหล่งพลังงานส่วนใหญ่ไว้ในมือ
เรื่องอาวุธ ผมไม่ขอวิเคราะห์ ใครมีอาวุธสุดยอดกว่าใคร เชื่อว่าไม่มีใครรู้จริงทั้งหมด นอกจากจะอยู่วงในสุดของแต่ละประเทศ และจะรู้จริงก็ตอนลงมือโซ้ยกันนั่นแหละครับ
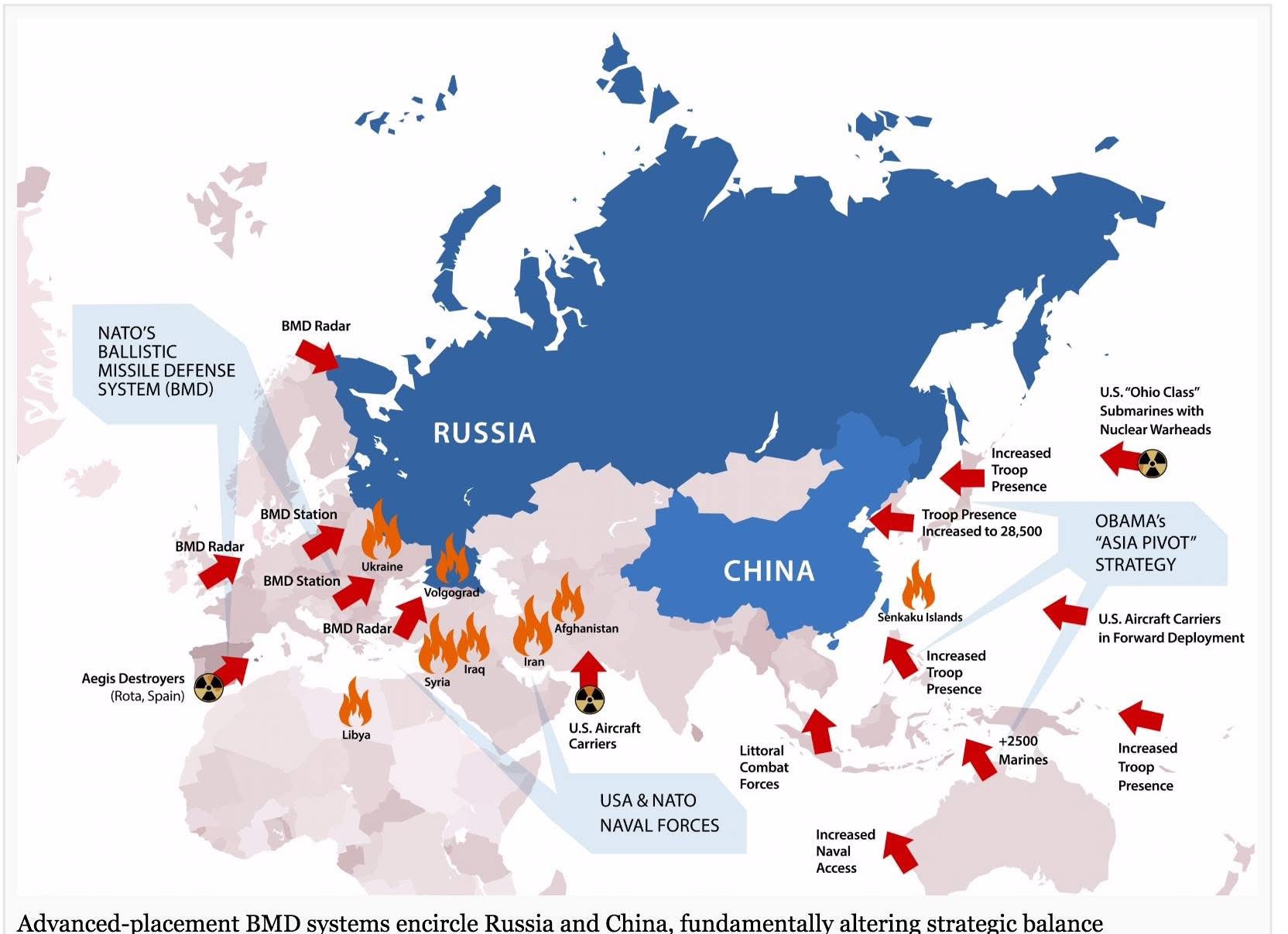
ส่วนยุทธศาสตร์ในการใช้อาวุธ จะใช้รูปแบบขนาด ระยะยิง จากฐานใดบ้าง มันคือแผนการรบ คนที่จะรู้แผนการรบจริงคือ ผู้บัญชาการรบ ผมเป็นแค่คนเล่านิทาน ไม่บังอาจไปวิจารณ์ฝ่ายใด คงบอกได้แต่ว่า ถ้าอเมริกาต้องเจอ รัสเซีย จีน อิหร่าน เกาหลีเหนือ และปากีสถาน พร้อมกัน ผมว่า อเมริกาคงคิดหนัก นาโตถึงยังเป็นใบ้ และญี่ปุ่น ที่คิดจะแบกถาดให้อเมริกา วันนี้ น่าจะยังใช้เวลาหาถาดอีกนาน
เรื่องกองกำลังของอเมริกา ต้องนับรวมทั้ง ทหารจริง ทหารรับจ้าง ทั้งของตัวเอง และของลูกหาบ ที่ครอบคลุม และแอบซ่อนอยู่ตามฐานทัพทั่วโลก และตอนนี้ คงต้องนับรวมเครือข่ายของผู้ก่อการร้าย หรือนักรบเติมเงินเข้าไปด้วย แปลว่า อเมริกาน่าจะมีแยะจริงๆ
แต่ผมก็ยังเชื่อว่า อเมริกา เดี่ยวๆ ไม่มีกำลังพลมากกว่า รัสเซียเดี่ยว หรือจีนเดี่ยวอยู่แล้ว ยิ่งกำลังพลรัสเซียบวกจีน อเมริกายิ่งไม่มีทางเทียบ อเมริกาจึงต้องเช็คชื่อ เรียกลูกหาบมาเกือบทั้งโลก อย่างที่อเมริกากำลังดำเนินการอยู่
คุณพี่ปูติน เดินหมากรุกเข้าไปในซีเรีย นี่จะเต็ม 3 เดือนแล้วนะครับ อเมริกายังเล่นหมากหลบ หมากเลี่ยง หมากเขก แต่ยังไม่ออกหมากรุกกลับ เข้าใจว่า คงยังเล่นหมากเก็บ “นับหัว” เอาเข้าคอกให้ครบเสียก่อน
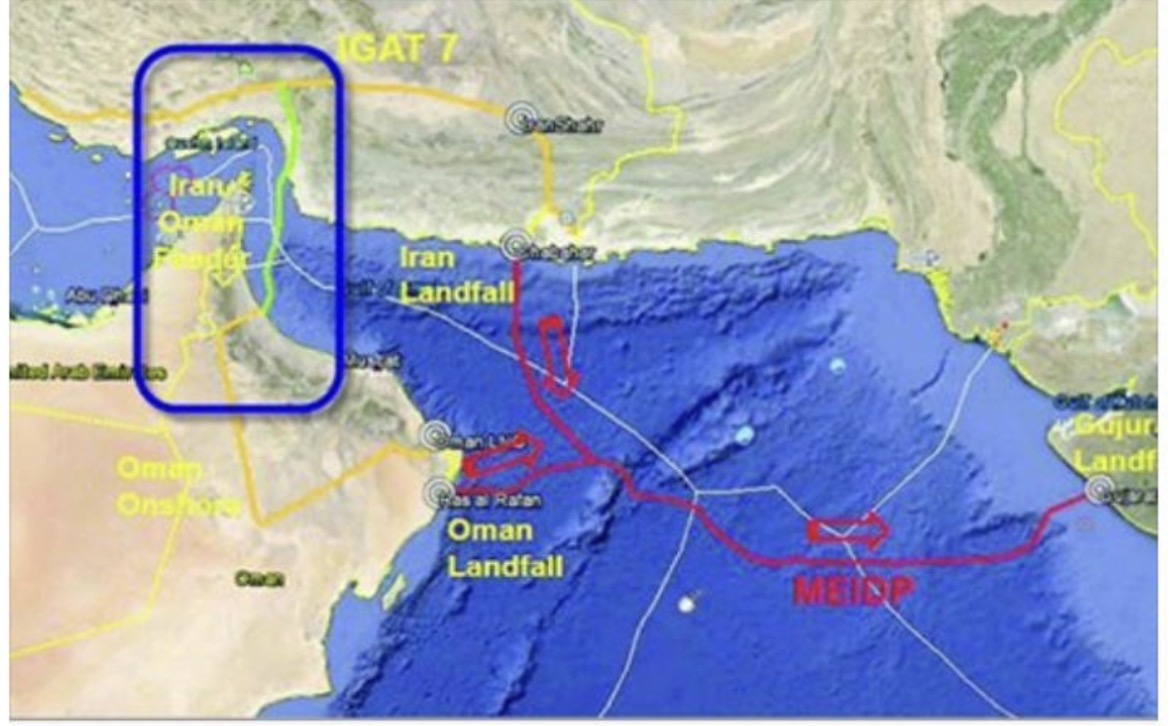
ส่วนเรื่องครอบครองแหล่งพลังงานส่วนใหญ่ไว้ในมือ เล่านิทานมา 2 ปีกว่า มาจนถึงเรื่องนี้ ตอนนี้ คิดว่าอเมริกาพูดได้เต็มปากหรือไม่ว่า ครอบครองแหล่งพลังงานส่วนใหญ่ของโลกไว้ได้แล้ว
มันก็ย้อนกลับมาที่เดิมว่า ยุทธศาสตร์ที่แต่ละฝ่ายใช้ และการเดินหมากตามยุทธศาสตร์ได้ผลอย่างไร การเดินหมากแบบลุยกินดะไปเรื่อยๆ ไม่แน่ว่า จะทำให้ชนะเสมอไป ขณะเดียวกัน การเดินหมาก ที่เหมือนขยับไม่กี่ตา แต่ขยับอีกที ก็รุกฆาตแล้ว ก็อาจเกิดขึ้นได้เหมือนกัน
ตลอดเวลา 70 ปีที่ผ่านมา อเมริกาเดินหมาก เหมือนกินดะได้ไปเกือบทั่วโลกแล้ว แต่การเดินหมากช่วงหลังของอเมริกา ดันสะดุดหัวแม่ตีนตัวเอง หัวทิ่มอย่างไม่น่าเชื่อ จากกระดาษซับไพรม์ใบบางๆ ที่ทำให้ตอนนี้อเมริกายังกระเป๋าฉีก ตูดขาด แต่อเมริกาสร้างเรื่องอื่นขึ้นมากลบ สื่อก็ช่วยพาเลี้ยว ชาวบ้านก็เลยลืม
ปี ค.ศ.2007 เมื่ออเมริกาเกิดวิกฤติทางเศรษฐกิจ จากเรื่องซับไพรม์ subprime ที่บริษัทเงินทุนจอมตะกละของอเมริกา เอาเอกสารลูกหนี้เงินกู้ซื้อบ้าน ไปขายลดต่ออีกหลายทอด จนไหม้เกรียม ลูกหนี้คนเดียว มีเจ้าหนี้ยืนเรียงคิวคอย พอเศรษฐกิจไม่ดี ลูกหนี้เจ็ง ไม่มีเงินผ่อนส่ง ไอ้พวกที่ซื้อไว้เป็นทอดๆ เรียงคิวคอย ก็ม่อยกะรอก ล้มตามกันเป็นพรวน และทำให้เศรษฐกิจอเมริกาสะอึกพรวด นักการเงินแก้ปัญหาหนี้เสียของบริษัทการเงิน ด้วยการเอาเงินรัฐมาอุ้มบริษัทการเงินเป็นจำนวนมหาศาล ตามสูตรสำเร็จ หลังจากนั้น ก็ลามไปกันใหญ่ และวันนี้อเมริกาก็มีหนี้กองโต ต้องลดงบ ตัดงบ ที่รวมไปถึงงบทางกองทัพด้วย
สรุปสั้นๆ ว่า อเมริกาตูดขาดมาเกือบสิบปีแล้ว และตอนนี้ก็ยังขาดอยู่ แต่ยังต้องทำหน้าใหญ่เอาไว้ แต่พินิจให้ดีๆ เถิดครับ หน้า พณ.ใบตองแห้ง กับ พณ.กลาโหม เวลาแถลงอะไรเกี่ยวกับเรื่องความมั่นคง ที่ต้องยกกองกำลังเข้าไปที่ไหน ทำหน้าเหมือนกับกินข้าวบูดมันเน่ามาทั้งนั้น แถมถ้าจำเป็นต้องส่งกำลังไปเพื่อรักษาหน้า ก็เป็นหลักร้อย ส่วนอาวุธ ส่วนใหญ่ก็เป็นโดรน ไม่มีคนขับ อเมริกาถึงยืนยันว่า no boots on the ground อยู่ตลอดเวลาได้แต่คอยชี้นิ้วสั่ง โอลอง เอ็งไปซิ แคมารอน เอ็งด้วย เอะ แล้วอเมริกาหายไปไหน แค่ส่งไปที่ละร้อย สองร้อยคน แถวซีเรีย อีรัค ขายหน้าพี่เบิ้มหมด
แต่ถึงอย่างนั้น เป็นประเทศมหาอำนาจมา 70 ปี สั่งซ้ายหันขวาหัน ให้มาเลียมือเลียตีนได้หมด แค่ตูดขาดไม่ถึง 10 ปี หมากเด็ด หายหมด หมากรุก ไม่มี อย่างนั้นหรือครับ แบบนี้จะแปลว่าอะไร
แปลว่า อเมริกาซ่อนหมากเด็ด เตรียมไว้รุกฆาต หรือแปลว่าอเมริการบไม่เป็น หรือไม่มีปัญญายกทัพมารบแล้ว…
น่าสังเกตว่า อเมริกาอาจจะถนัดแต่การรบแบบปฏิบัติการ หรือรบแบบกองโจรไปปล้นประเทศที่ไม่ทางสู้มากกว่า หรือไม่ก็ใช้ทหารรับจ้าง ที่เรียกเสียหรูว่า contractor หรือ security advisor เป็นผู้ไป “ดำเนินการ” ไม่ใช่การรบจริง เต็มรูปแบบทางกำลังทหาร
ตลอดเวลาประมาณ 70 ที่ผ่านมา มีเพียง 2,3 ครั้งเท่านั้น ที่เป็นการรบจริง คือ ในสงครามเกาหลี และสงครามเวียตนามเท่านั้น นั่นมันก็กว่า 50 ปีมาแล้ว นอกนั้น มันเป็นการปฏิบัติการโดยพวกทหารรับจ้าง กับทหารนอกระบบ ที่เรียกว่า “stay behind” เครือข่ายหลังฉาก หรือเครือข่ายที่ซ่อนเร้นเกือบทั้งสิ้น แม้ในสมัยสงครามอิรัค อเมริกาก็ใช้ทหารรับจ้างมาก พอๆกับทหารในกองทัพ ถึงได้งบบานฉิบหายไป ส่วนนาโต้เอง ก็ไม่ได้มีกองกำลังทหารจริงทั้งหมด ใช้เครือข่าย stay behind กับ contractor มากเช่นเดียวกัน
แต่ระหว่างเกือบ 10 ที่เศรษฐกิจอเมริกาสะอึก ฝั่งรัสเซียจีน แม้จะไม่ได้ฉลุย แต่ก็น่าจะมีอะไรดี ไม่งั้นรัสเซียคงไม่หาญกล้ายกพลเข้าไปที่ซีเรีย และการยกพลของรัสเซียครั้งนี้ คุณพี่ปูตินเล่นยกมาเป็นกองทัพ ทั้งบกเรืออากาศ มีเรือรบ มีเครื่องบิน มีรถถัง ทหารราบจำนวนแสน
แล้วอเมริกาเดินหมากยังไงครับ ตอนนี้เป็นหมากพูด หรือหมากพ่น อย่าเป็นหมากเผ่นก็แล้วกัน
เมื่อไม่นานมานี่ พณ. ใบตองแห้ง ออกมาพูดเองว่า ไอซิสแผ่วแล้วนะ พื้นที่ที่ยึดไปในอิรัคเหลือน้อยแล้ว ที่ซีเรียก็เช่นเดียวกัน หายไปแยะ ก็ใช่ซิ รัสเซียถล่มเสียราบ กองกำลังร่วมของอเมริกา เข้าไป 4 ปีกว่า ไอซิสมีแต่งอกเพิ่ม รัสเซียมาไม่ถึง 3 เดือน ไอซิสมุดรูหนีออกไปทางลิเบียหมด แต่ พณ.ใบตอง แห้งยังออกมาพูดเอาคะแนน แถมขู่พวกตัวหัวหน้าไอซิสอีกว่า you are next ต่อไปคือพวกเอ็ง ….เป็นการขู่ผ่านสื่อออกทีวี ….เห็นสันดานใบตองแห้งชัดจริงๆ
ตกลงถึงวันนี้ ผมยังไม่เห็นหมากเด็ด หมากรุก อะไรที่จะทำให้ผมเชื่อว่า อเมริกาเป็นนักยุทธศาสตร์ทางด้านการรบ เอาละ มันยังไม่ถึงเวลารบจริง เพราะฉะนั้นตอนนี้ ต้องดูการเดินหมาก “เตรียมรบ” มากกว่า ว่าของใครล้ำลึกเด็ดขาดกว่ากัน คือดูตัวหมาก ที่แต่ละฝ่าย เลือกเอามาเดิน เลือกกิน หรือเลือกทิ้ง
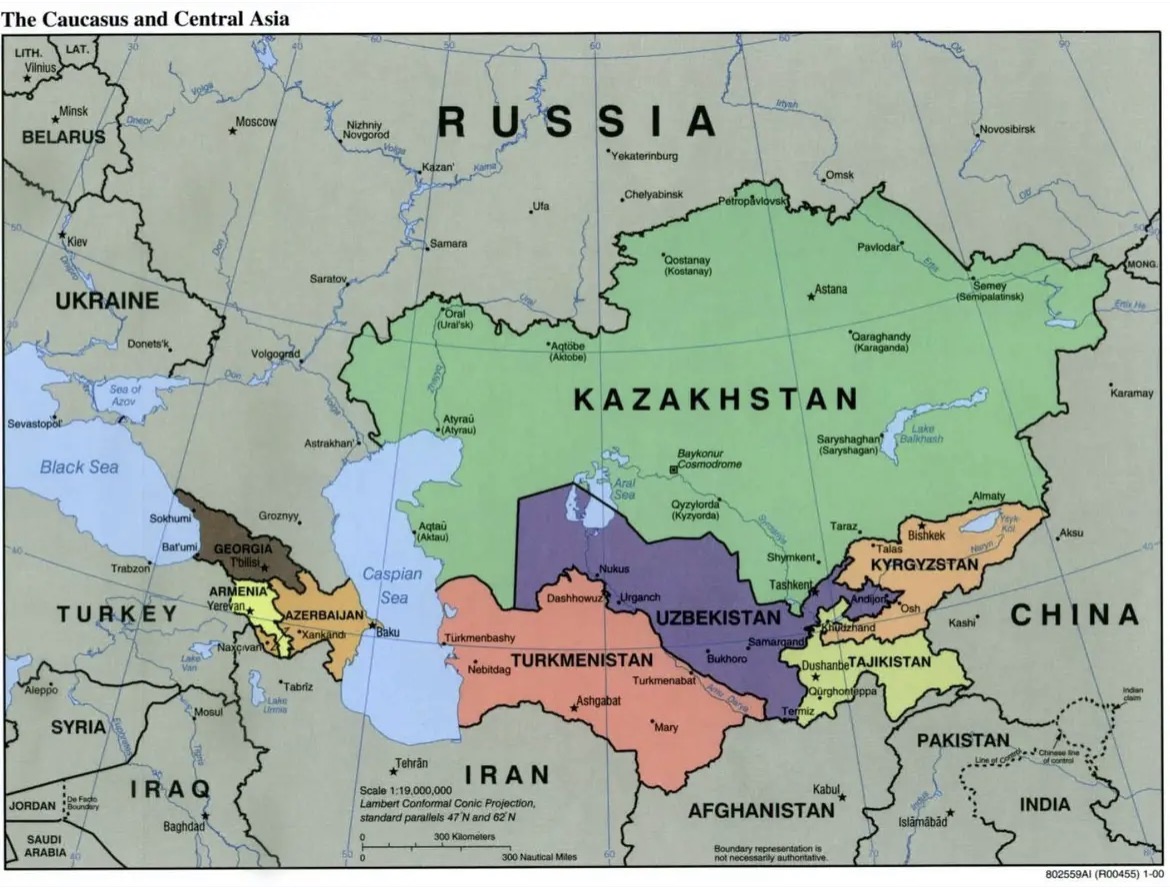
ตามทฤษฏีของไอ้แสบเบรสินสกี้ หมากตัวสำคัญในตะวันออกกลาง มี 2 ตัว คือ อิหร่าน กับตุรกี วันนี้เราเห็นชัดว่า อิหร่าน เปิดเผยว่าอยู่ขั้วรัสเซียจีน แผนบีบด้วยนิวเคลียร์ บีบอิหร่านไม่สำเร็จ
ในตะวันออกกลางจึงเหลือตุรกี ที่เป็นหมากให้ดูว่า รัสเซียเสียตุรกี หรือรัสเซียถีบตุรกีทิ้ง และถ้าอเมริกาเลือกตุรกีมาเป็นหมากฝ่ายตัว เป็นเรื่องดี หรือ ซวยของอเมริกา
ถัดมาเป็นหมาก แถวมหาสมุทรอินเดีย ใกล้บ้านเราเข้ามาหน่อย
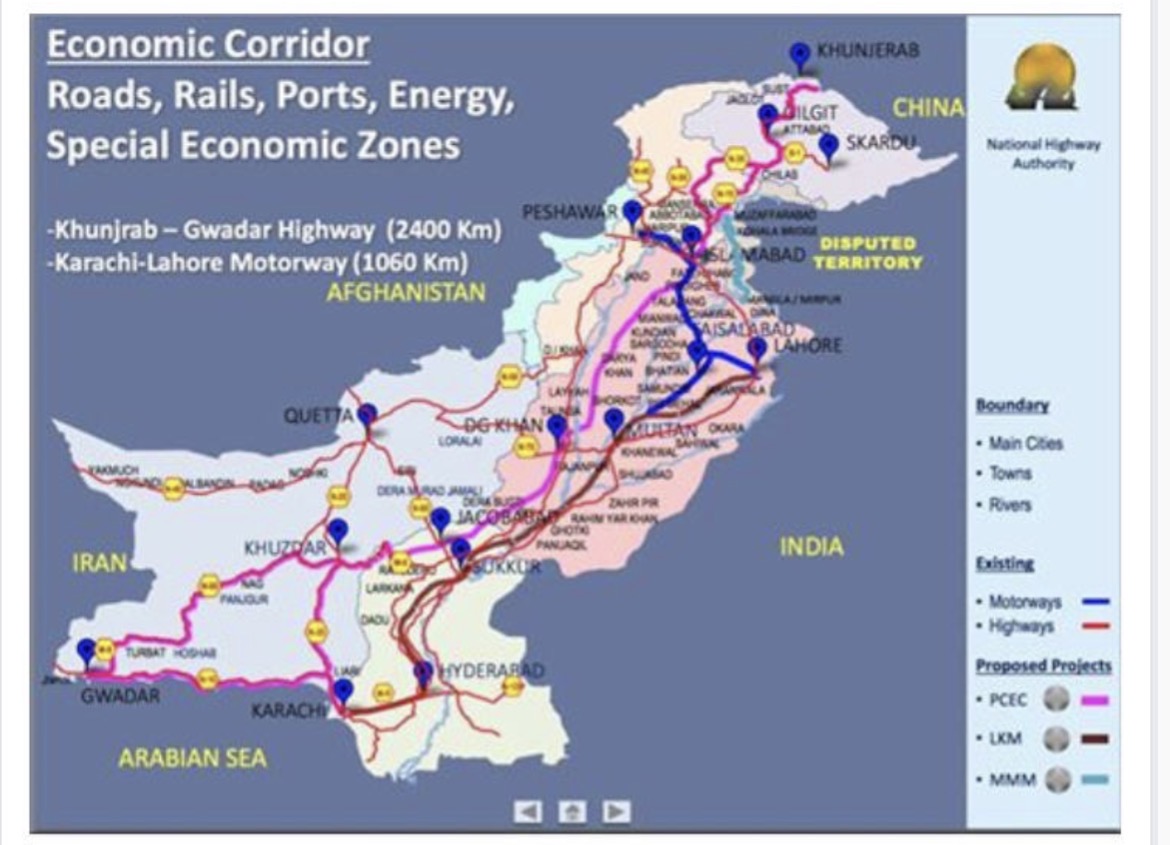
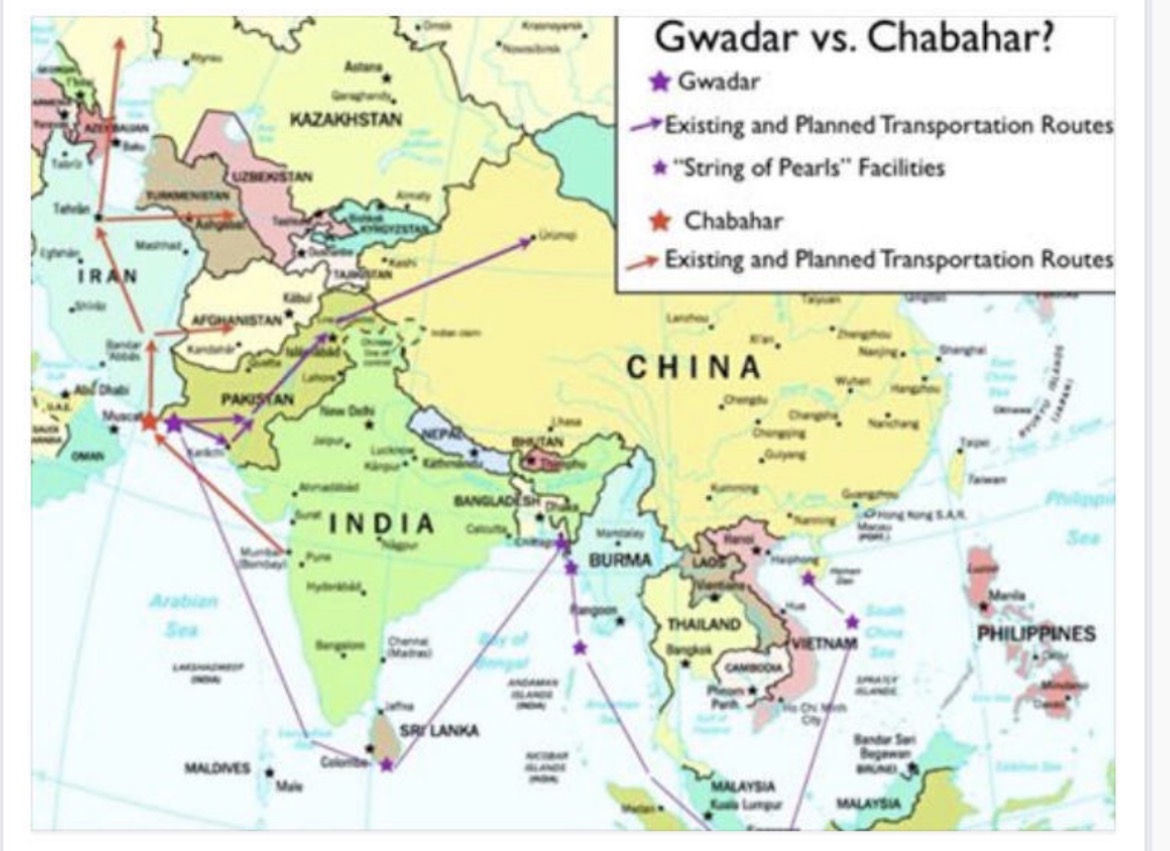
ปากีสถาน ก็เป็นหมากที่น่าสนใจตามดูเช่นเดียวกัน ว่า ปากีสถานทิ้งอเมริกา หรืออเมริกาทิ้งปากีสถาน และมาเลือกอินเดีย เพราะหมาก 2 ตัวนี้ คงจะอยู่ข้างเดียวกันยาก แม้ตอนนี้จะมีความพยายาม แต่นั่นแหละ แขกเป็นนักเล่นกล ไม่รู้ว่าอเมริกาจะรู้จักตำนานนี้ไหม
อเมริกา จะเลือกเดินหมากอินเดียเพราะอะไร และอเมริกาได้ หรืออเมริกาเสีย ในการเสียปากีสถาน และ (ยังไม่แน่ว่าจะ) ได้ อินเดีย
ช่วงนี้ดูหมาก 3 ตัวนี้ไว้เท่านั้นแหละครับ ตุรกี ปากีสถาน อืนเดีย การเดินหมาก 3 ตัวนี้ จะทำให้เห็นว่า ยุทธศาตร์ฝ่ายไหน ลึกซึ้ง และฝ่ายใด กำลังเดินหมาก รุก……
หลังปีใหม่ ค่อยมาอ่านนิทานต่อนะครับ
ระหว่างข้ามปี ใช้ชีวิตสบายๆ สวดมนต์ ไหว้พระ ทำบุญ ทำกุศล ถวายพระบาทสมเด็จพระเจ้าอยู่หัว และสมเด็จพระนางเจ้าพระบรมราชินีนาถ ให้เกิดสวัสดิมงคลแก่บ้านเมือง ตัวเองและครอบครัว และโชคดีตลอดปีใหม่ นะครับ
สวัสดีครับ
คนเล่านิทาน
31 ธ.ค. 2558
นิทานเรื่องจริง เรื่อง “หมากรุก”
ตอน 10 (จบ)
สรุปว่า ยุทธศาสตร์ของอเมริกาคือ ยุทธศาสตร์เพื่อการ “ครองโลกแต่ผู้เดียว” ที่ไม่เคยเปลี่ยนแปลงมาตลอด 70 ปีที่ผ่านมา
ส่วนยุทธศาสตร์ของรัสเซีย น่าจะเป็นยุทธศาสตร์ “รัสเซียแกร่งกล้า” ที่สร้างบ้านเมืองให้แข็งแกร่งขึ้นมาใหม่ได้ และพร้อมแล้วที่จะบอกกับอเมริกาว่า “พอได้แล้วนะ” อเมริกาไม่ได้เป็นผู้กำหนดชะตาของทุกประเทศในโลกนี้อีกแล้ว การก้าวเข้าไปในซีเรีย และตะวันออกกลางของรัสเซีย มันแปลได้อย่างนั้น
และยุทธศาสตร์ของจีน น่าจะเป็นยุทธศาสตร์ “จีนยิ่งใหญ่” หรือประเภทมังกรทะยานฟ้า เรื่องปิดล้อมจีนจบแล้ว อย่าได้คิดเชียวว่า จะมีใครมาปิด มาล้อมจีนได้อีก ไม่ว่าทางด้านเศรษฐกิจ หรือกำลังทหาร ไม่มีทางแล้ว
และตามยุทธศาสตร์ของทั้ง 3 ผู้ยิ่งใหญ่ อย่างน้อยต้องมีองค์ประกอบพื้นฐานเช่นเดียวกัน 3 เรื่อง เพื่อจะเดินหน้าตามแผนของตัวในช่วง 20 ปีที่ผ่านมา คือ
– มีอาวุธที่สุดยอด
– มีกองกำลังที่ยิ่งใหญ่
– ได้ครอบครองแหล่งพลังงานส่วนใหญ่ไว้ในมือ
เรื่องอาวุธ ผมไม่ขอวิเคราะห์ ใครมีอาวุธสุดยอดกว่าใคร เชื่อว่าไม่มีใครรู้จริงทั้งหมด นอกจากจะอยู่วงในสุดของแต่ละประเทศ และจะรู้จริงก็ตอนลงมือโซ้ยกันนั่นแหละครับ
ส่วนยุทธศาสตร์ในการใช้อาวุธ จะใช้รูปแบบขนาด ระยะยิง จากฐานใดบ้าง มันคือแผนการรบ คนที่จะรู้แผนการรบจริงคือ ผู้บัญชาการรบ ผมเป็นแค่คนเล่านิทาน ไม่บังอาจไปวิจารณ์ฝ่ายใด คงบอกได้แต่ว่า ถ้าอเมริกาต้องเจอ รัสเซีย จีน อิหร่าน เกาหลีเหนือ และปากีสถาน พร้อมกัน ผมว่า อเมริกาคงคิดหนัก นาโตถึงยังเป็นใบ้ และญี่ปุ่น ที่คิดจะแบกถาดให้อเมริกา วันนี้ น่าจะยังใช้เวลาหาถาดอีกนาน
เรื่องกองกำลังของอเมริกา ต้องนับรวมทั้ง ทหารจริง ทหารรับจ้าง ทั้งของตัวเอง และของลูกหาบ ที่ครอบคลุม และแอบซ่อนอยู่ตามฐานทัพทั่วโลก และตอนนี้ คงต้องนับรวมเครือข่ายของผู้ก่อการร้าย หรือนักรบเติมเงินเข้าไปด้วย แปลว่า อเมริกาน่าจะมีแยะจริงๆ
แต่ผมก็ยังเชื่อว่า อเมริกา เดี่ยวๆ ไม่มีกำลังพลมากกว่า รัสเซียเดี่ยว หรือจีนเดี่ยวอยู่แล้ว ยิ่งกำลังพลรัสเซียบวกจีน อเมริกายิ่งไม่มีทางเทียบ อเมริกาจึงต้องเช็คชื่อ เรียกลูกหาบมาเกือบทั้งโลก อย่างที่อเมริกากำลังดำเนินการอยู่
คุณพี่ปูติน เดินหมากรุกเข้าไปในซีเรีย นี่จะเต็ม 3 เดือนแล้วนะครับ อเมริกายังเล่นหมากหลบ หมากเลี่ยง หมากเขก แต่ยังไม่ออกหมากรุกกลับ เข้าใจว่า คงยังเล่นหมากเก็บ “นับหัว” เอาเข้าคอกให้ครบเสียก่อน
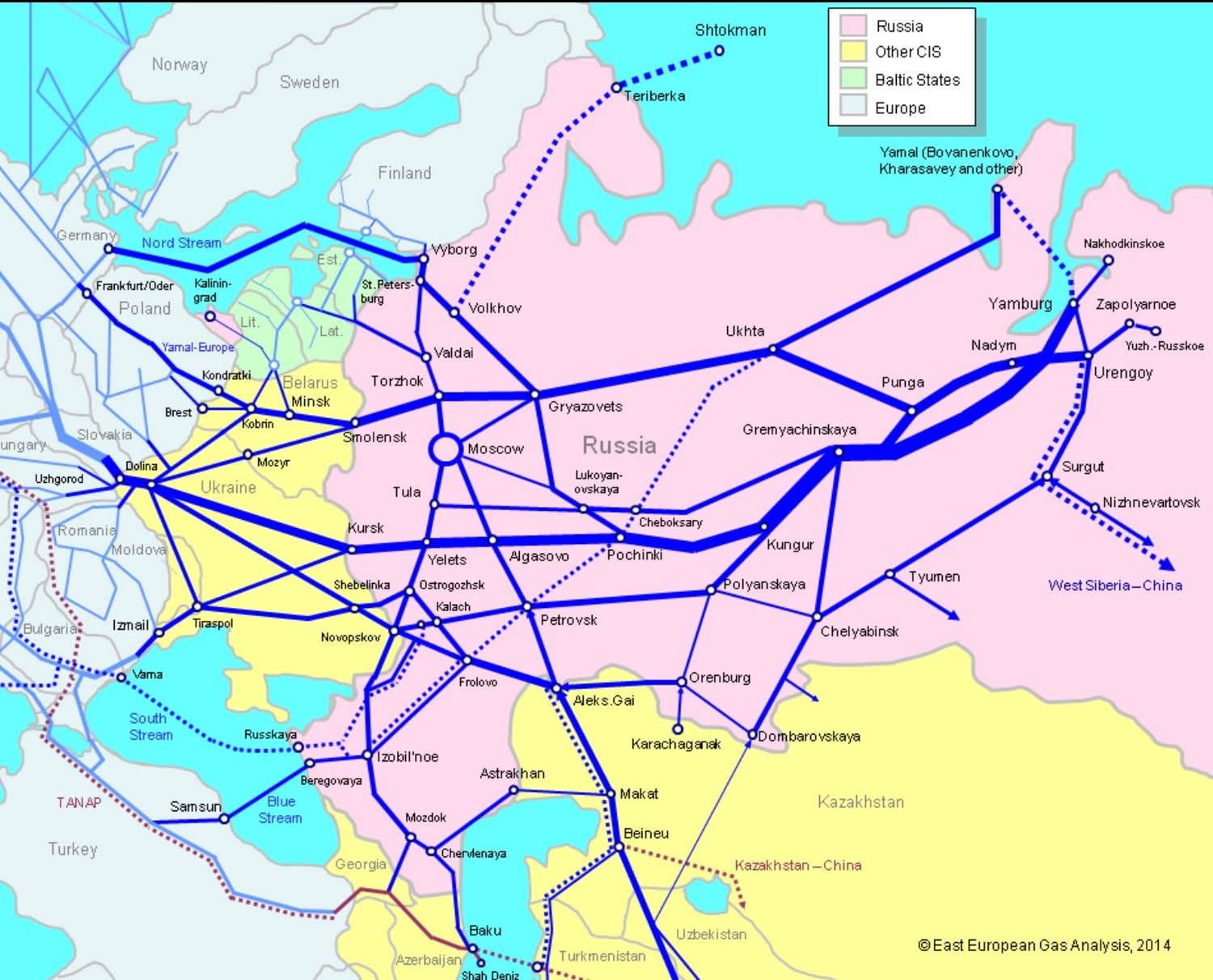
ส่วนเรื่องครอบครองแหล่งพลังงานส่วนใหญ่ไว้ในมือ เล่านิทานมา 2 ปีกว่า มาจนถึงเรื่องนี้ ตอนนี้ คิดว่าอเมริกาพูดได้เต็มปากหรือไม่ว่า ครอบครองแหล่งพลังงานส่วนใหญ่ของโลกไว้ได้แล้ว
มันก็ย้อนกลับมาที่เดิมว่า ยุทธศาสตร์ที่แต่ละฝ่ายใช้ และการเดินหมากตามยุทธศาสตร์ได้ผลอย่างไร การเดินหมากแบบลุยกินดะไปเรื่อยๆ ไม่แน่ว่า จะทำให้ชนะเสมอไป ขณะเดียวกัน การเดินหมาก ที่เหมือนขยับไม่กี่ตา แต่ขยับอีกที ก็รุกฆาตแล้ว ก็อาจเกิดขึ้นได้เหมือนกัน
ตลอดเวลา 70 ปีที่ผ่านมา อเมริกาเดินหมาก เหมือนกินดะได้ไปเกือบทั่วโลกแล้ว แต่การเดินหมากช่วงหลังของอเมริกา ดันสะดุดหัวแม่ตีนตัวเอง หัวทิ่มอย่างไม่น่าเชื่อ จากกระดาษซับไพรม์ใบบางๆ ที่ทำให้ตอนนี้อเมริกายังกระเป๋าฉีก ตูดขาด แต่อเมริกาสร้างเรื่องอื่นขึ้นมากลบ สื่อก็ช่วยพาเลี้ยว ชาวบ้านก็เลยลืม
ปี ค.ศ.2007 เมื่ออเมริกาเกิดวิกฤติทางเศรษฐกิจ จากเรื่องซับไพรม์ subprime ที่บริษัทเงินทุนจอมตะกละของอเมริกา เอาเอกสารลูกหนี้เงินกู้ซื้อบ้าน ไปขายลดต่ออีกหลายทอด จนไหม้เกรียม ลูกหนี้คนเดียว มีเจ้าหนี้ยืนเรียงคิวคอย พอเศรษฐกิจไม่ดี ลูกหนี้เจ็ง ไม่มีเงินผ่อนส่ง ไอ้พวกที่ซื้อไว้เป็นทอดๆ เรียงคิวคอย ก็ม่อยกะรอก ล้มตามกันเป็นพรวน และทำให้เศรษฐกิจอเมริกาสะอึกพรวด นักการเงินแก้ปัญหาหนี้เสียของบริษัทการเงิน ด้วยการเอาเงินรัฐมาอุ้มบริษัทการเงินเป็นจำนวนมหาศาล ตามสูตรสำเร็จ หลังจากนั้น ก็ลามไปกันใหญ่ และวันนี้อเมริกาก็มีหนี้กองโต ต้องลดงบ ตัดงบ ที่รวมไปถึงงบทางกองทัพด้วย
สรุปสั้นๆ ว่า อเมริกาตูดขาดมาเกือบสิบปีแล้ว และตอนนี้ก็ยังขาดอยู่ แต่ยังต้องทำหน้าใหญ่เอาไว้ แต่พินิจให้ดีๆ เถิดครับ หน้า พณ.ใบตองแห้ง กับ พณ.กลาโหม เวลาแถลงอะไรเกี่ยวกับเรื่องความมั่นคง ที่ต้องยกกองกำลังเข้าไปที่ไหน ทำหน้าเหมือนกับกินข้าวบูดมันเน่ามาทั้งนั้น แถมถ้าจำเป็นต้องส่งกำลังไปเพื่อรักษาหน้า ก็เป็นหลักร้อย ส่วนอาวุธ ส่วนใหญ่ก็เป็นโดรน ไม่มีคนขับ อเมริกาถึงยืนยันว่า no boots on the ground อยู่ตลอดเวลาได้แต่คอยชี้นิ้วสั่ง โอลอง เอ็งไปซิ แคมารอน เอ็งด้วย เอะ แล้วอเมริกาหายไปไหน แค่ส่งไปที่ละร้อย สองร้อยคน แถวซีเรีย อีรัค ขายหน้าพี่เบิ้มหมด
แต่ถึงอย่างนั้น เป็นประเทศมหาอำนาจมา 70 ปี สั่งซ้ายหันขวาหัน ให้มาเลียมือเลียตีนได้หมด แค่ตูดขาดไม่ถึง 10 ปี หมากเด็ด หายหมด หมากรุก ไม่มี อย่างนั้นหรือครับ แบบนี้จะแปลว่าอะไร
แปลว่า อเมริกาซ่อนหมากเด็ด เตรียมไว้รุกฆาต หรือแปลว่าอเมริการบไม่เป็น หรือไม่มีปัญญายกทัพมารบแล้ว…
น่าสังเกตว่า อเมริกาอาจจะถนัดแต่การรบแบบปฏิบัติการ หรือรบแบบกองโจรไปปล้นประเทศที่ไม่ทางสู้มากกว่า หรือไม่ก็ใช้ทหารรับจ้าง ที่เรียกเสียหรูว่า contractor หรือ security advisor เป็นผู้ไป “ดำเนินการ” ไม่ใช่การรบจริง เต็มรูปแบบทางกำลังทหาร
ตลอดเวลาประมาณ 70 ที่ผ่านมา มีเพียง 2,3 ครั้งเท่านั้น ที่เป็นการรบจริง คือ ในสงครามเกาหลี และสงครามเวียตนามเท่านั้น นั่นมันก็กว่า 50 ปีมาแล้ว นอกนั้น มันเป็นการปฏิบัติการโดยพวกทหารรับจ้าง กับทหารนอกระบบ ที่เรียกว่า “stay behind” เครือข่ายหลังฉาก หรือเครือข่ายที่ซ่อนเร้นเกือบทั้งสิ้น แม้ในสมัยสงครามอิรัค อเมริกาก็ใช้ทหารรับจ้างมาก พอๆกับทหารในกองทัพ ถึงได้งบบานฉิบหายไป ส่วนนาโต้เอง ก็ไม่ได้มีกองกำลังทหารจริงทั้งหมด ใช้เครือข่าย stay behind กับ contractor มากเช่นเดียวกัน
แต่ระหว่างเกือบ 10 ที่เศรษฐกิจอเมริกาสะอึก ฝั่งรัสเซียจีน แม้จะไม่ได้ฉลุย แต่ก็น่าจะมีอะไรดี ไม่งั้นรัสเซียคงไม่หาญกล้ายกพลเข้าไปที่ซีเรีย และการยกพลของรัสเซียครั้งนี้ คุณพี่ปูตินเล่นยกมาเป็นกองทัพ ทั้งบกเรืออากาศ มีเรือรบ มีเครื่องบิน มีรถถัง ทหารราบจำนวนแสน
แล้วอเมริกาเดินหมากยังไงครับ ตอนนี้เป็นหมากพูด หรือหมากพ่น อย่าเป็นหมากเผ่นก็แล้วกัน
เมื่อไม่นานมานี่ พณ. ใบตองแห้ง ออกมาพูดเองว่า ไอซิสแผ่วแล้วนะ พื้นที่ที่ยึดไปในอิรัคเหลือน้อยแล้ว ที่ซีเรียก็เช่นเดียวกัน หายไปแยะ ก็ใช่ซิ รัสเซียถล่มเสียราบ กองกำลังร่วมของอเมริกา เข้าไป 4 ปีกว่า ไอซิสมีแต่งอกเพิ่ม รัสเซียมาไม่ถึง 3 เดือน ไอซิสมุดรูหนีออกไปทางลิเบียหมด แต่ พณ.ใบตอง แห้งยังออกมาพูดเอาคะแนน แถมขู่พวกตัวหัวหน้าไอซิสอีกว่า you are next ต่อไปคือพวกเอ็ง ….เป็นการขู่ผ่านสื่อออกทีวี ….เห็นสันดานใบตองแห้งชัดจริงๆ
ตกลงถึงวันนี้ ผมยังไม่เห็นหมากเด็ด หมากรุก อะไรที่จะทำให้ผมเชื่อว่า อเมริกาเป็นนักยุทธศาสตร์ทางด้านการรบ เอาละ มันยังไม่ถึงเวลารบจริง เพราะฉะนั้นตอนนี้ ต้องดูการเดินหมาก “เตรียมรบ” มากกว่า ว่าของใครล้ำลึกเด็ดขาดกว่ากัน คือดูตัวหมาก ที่แต่ละฝ่าย เลือกเอามาเดิน เลือกกิน หรือเลือกทิ้ง
ตามทฤษฏีของไอ้แสบเบรสินสกี้ หมากตัวสำคัญในตะวันออกกลาง มี 2 ตัว คือ อิหร่าน กับตุรกี วันนี้เราเห็นชัดว่า อิหร่าน เปิดเผยว่าอยู่ขั้วรัสเซียจีน แผนบีบด้วยนิวเคลียร์ บีบอิหร่านไม่สำเร็จ
ในตะวันออกกลางจึงเหลือตุรกี ที่เป็นหมากให้ดูว่า รัสเซียเสียตุรกี หรือรัสเซียถีบตุรกีทิ้ง และถ้าอเมริกาเลือกตุรกีมาเป็นหมากฝ่ายตัว เป็นเรื่องดี หรือ ซวยของอเมริกา
ถัดมาเป็นหมาก แถวมหาสมุทรอินเดีย ใกล้บ้านเราเข้ามาหน่อย
ปากีสถาน ก็เป็นหมากที่น่าสนใจตามดูเช่นเดียวกัน ว่า ปากีสถานทิ้งอเมริกา หรืออเมริกาทิ้งปากีสถาน และมาเลือกอินเดีย เพราะหมาก 2 ตัวนี้ คงจะอยู่ข้างเดียวกันยาก แม้ตอนนี้จะมีความพยายาม แต่นั่นแหละ แขกเป็นนักเล่นกล ไม่รู้ว่าอเมริกาจะรู้จักตำนานนี้ไหม
อเมริกา จะเลือกเดินหมากอินเดียเพราะอะไร และอเมริกาได้ หรืออเมริกาเสีย ในการเสียปากีสถาน และ (ยังไม่แน่ว่าจะ) ได้ อินเดีย
ช่วงนี้ดูหมาก 3 ตัวนี้ไว้เท่านั้นแหละครับ ตุรกี ปากีสถาน อืนเดีย การเดินหมาก 3 ตัวนี้ จะทำให้เห็นว่า ยุทธศาตร์ฝ่ายไหน ลึกซึ้ง และฝ่ายใด กำลังเดินหมาก รุก……
หลังปีใหม่ ค่อยมาอ่านนิทานต่อนะครับ
ระหว่างข้ามปี ใช้ชีวิตสบายๆ สวดมนต์ ไหว้พระ ทำบุญ ทำกุศล ถวายพระบาทสมเด็จพระเจ้าอยู่หัว และสมเด็จพระนางเจ้าพระบรมราชินีนาถ ให้เกิดสวัสดิมงคลแก่บ้านเมือง ตัวเองและครอบครัว และโชคดีตลอดปีใหม่ นะครับ
สวัสดีครับ
คนเล่านิทาน
31 ธ.ค. 2558
หมากรุก ตอนที่ 10
นิทานเรื่องจริง เรื่อง “หมากรุก”
ตอน 10 (จบ)
สรุปว่า ยุทธศาสตร์ของอเมริกาคือ ยุทธศาสตร์เพื่อการ “ครองโลกแต่ผู้เดียว” ที่ไม่เคยเปลี่ยนแปลงมาตลอด 70 ปีที่ผ่านมา
ส่วนยุทธศาสตร์ของรัสเซีย น่าจะเป็นยุทธศาสตร์ “รัสเซียแกร่งกล้า” ที่สร้างบ้านเมืองให้แข็งแกร่งขึ้นมาใหม่ได้ และพร้อมแล้วที่จะบอกกับอเมริกาว่า “พอได้แล้วนะ” อเมริกาไม่ได้เป็นผู้กำหนดชะตาของทุกประเทศในโลกนี้อีกแล้ว การก้าวเข้าไปในซีเรีย และตะวันออกกลางของรัสเซีย มันแปลได้อย่างนั้น
และยุทธศาสตร์ของจีน น่าจะเป็นยุทธศาสตร์ “จีนยิ่งใหญ่” หรือประเภทมังกรทะยานฟ้า เรื่องปิดล้อมจีนจบแล้ว อย่าได้คิดเชียวว่า จะมีใครมาปิด มาล้อมจีนได้อีก ไม่ว่าทางด้านเศรษฐกิจ หรือกำลังทหาร ไม่มีทางแล้ว
และตามยุทธศาสตร์ของทั้ง 3 ผู้ยิ่งใหญ่ อย่างน้อยต้องมีองค์ประกอบพื้นฐานเช่นเดียวกัน 3 เรื่อง เพื่อจะเดินหน้าตามแผนของตัวในช่วง 20 ปีที่ผ่านมา คือ
– มีอาวุธที่สุดยอด
– มีกองกำลังที่ยิ่งใหญ่
– ได้ครอบครองแหล่งพลังงานส่วนใหญ่ไว้ในมือ
เรื่องอาวุธ ผมไม่ขอวิเคราะห์ ใครมีอาวุธสุดยอดกว่าใคร เชื่อว่าไม่มีใครรู้จริงทั้งหมด นอกจากจะอยู่วงในสุดของแต่ละประเทศ และจะรู้จริงก็ตอนลงมือโซ้ยกันนั่นแหละครับ
ส่วนยุทธศาสตร์ในการใช้อาวุธ จะใช้รูปแบบขนาด ระยะยิง จากฐานใดบ้าง มันคือแผนการรบ คนที่จะรู้แผนการรบจริงคือ ผู้บัญชาการรบ ผมเป็นแค่คนเล่านิทาน ไม่บังอาจไปวิจารณ์ฝ่ายใด คงบอกได้แต่ว่า ถ้าอเมริกาต้องเจอ รัสเซีย จีน อิหร่าน เกาหลีเหนือ และปากีสถาน พร้อมกัน ผมว่า อเมริกาคงคิดหนัก นาโตถึงยังเป็นใบ้ และญี่ปุ่น ที่คิดจะแบกถาดให้อเมริกา วันนี้ น่าจะยังใช้เวลาหาถาดอีกนาน
เรื่องกองกำลังของอเมริกา ต้องนับรวมทั้ง ทหารจริง ทหารรับจ้าง ทั้งของตัวเอง และของลูกหาบ ที่ครอบคลุม และแอบซ่อนอยู่ตามฐานทัพทั่วโลก และตอนนี้ คงต้องนับรวมเครือข่ายของผู้ก่อการร้าย หรือนักรบเติมเงินเข้าไปด้วย แปลว่า อเมริกาน่าจะมีแยะจริงๆ
แต่ผมก็ยังเชื่อว่า อเมริกา เดี่ยวๆ ไม่มีกำลังพลมากกว่า รัสเซียเดี่ยว หรือจีนเดี่ยวอยู่แล้ว ยิ่งกำลังพลรัสเซียบวกจีน อเมริกายิ่งไม่มีทางเทียบ อเมริกาจึงต้องเช็คชื่อ เรียกลูกหาบมาเกือบทั้งโลก อย่างที่อเมริกากำลังดำเนินการอยู่
คุณพี่ปูติน เดินหมากรุกเข้าไปในซีเรีย นี่จะเต็ม 3 เดือนแล้วนะครับ อเมริกายังเล่นหมากหลบ หมากเลี่ยง หมากเขก แต่ยังไม่ออกหมากรุกกลับ เข้าใจว่า คงยังเล่นหมากเก็บ “นับหัว” เอาเข้าคอกให้ครบเสียก่อน
ส่วนเรื่องครอบครองแหล่งพลังงานส่วนใหญ่ไว้ในมือ เล่านิทานมา 2 ปีกว่า มาจนถึงเรื่องนี้ ตอนนี้ คิดว่าอเมริกาพูดได้เต็มปากหรือไม่ว่า ครอบครองแหล่งพลังงานส่วนใหญ่ของโลกไว้ได้แล้ว
มันก็ย้อนกลับมาที่เดิมว่า ยุทธศาสตร์ที่แต่ละฝ่ายใช้ และการเดินหมากตามยุทธศาสตร์ได้ผลอย่างไร การเดินหมากแบบลุยกินดะไปเรื่อยๆ ไม่แน่ว่า จะทำให้ชนะเสมอไป ขณะเดียวกัน การเดินหมาก ที่เหมือนขยับไม่กี่ตา แต่ขยับอีกที ก็รุกฆาตแล้ว ก็อาจเกิดขึ้นได้เหมือนกัน
ตลอดเวลา 70 ปีที่ผ่านมา อเมริกาเดินหมาก เหมือนกินดะได้ไปเกือบทั่วโลกแล้ว แต่การเดินหมากช่วงหลังของอเมริกา ดันสะดุดหัวแม่ตีนตัวเอง หัวทิ่มอย่างไม่น่าเชื่อ จากกระดาษซับไพรม์ใบบางๆ ที่ทำให้ตอนนี้อเมริกายังกระเป๋าฉีก ตูดขาด แต่อเมริกาสร้างเรื่องอื่นขึ้นมากลบ สื่อก็ช่วยพาเลี้ยว ชาวบ้านก็เลยลืม
ปี ค.ศ.2007 เมื่ออเมริกาเกิดวิกฤติทางเศรษฐกิจ จากเรื่องซับไพรม์ subprime ที่บริษัทเงินทุนจอมตะกละของอเมริกา เอาเอกสารลูกหนี้เงินกู้ซื้อบ้าน ไปขายลดต่ออีกหลายทอด จนไหม้เกรียม ลูกหนี้คนเดียว มีเจ้าหนี้ยืนเรียงคิวคอย พอเศรษฐกิจไม่ดี ลูกหนี้เจ็ง ไม่มีเงินผ่อนส่ง ไอ้พวกที่ซื้อไว้เป็นทอดๆ เรียงคิวคอย ก็ม่อยกะรอก ล้มตามกันเป็นพรวน และทำให้เศรษฐกิจอเมริกาสะอึกพรวด นักการเงินแก้ปัญหาหนี้เสียของบริษัทการเงิน ด้วยการเอาเงินรัฐมาอุ้มบริษัทการเงินเป็นจำนวนมหาศาล ตามสูตรสำเร็จ หลังจากนั้น ก็ลามไปกันใหญ่ และวันนี้อเมริกาก็มีหนี้กองโต ต้องลดงบ ตัดงบ ที่รวมไปถึงงบทางกองทัพด้วย
สรุปสั้นๆ ว่า อเมริกาตูดขาดมาเกือบสิบปีแล้ว และตอนนี้ก็ยังขาดอยู่ แต่ยังต้องทำหน้าใหญ่เอาไว้ แต่พินิจให้ดีๆ เถิดครับ หน้า พณ.ใบตองแห้ง กับ พณ.กลาโหม เวลาแถลงอะไรเกี่ยวกับเรื่องความมั่นคง ที่ต้องยกกองกำลังเข้าไปที่ไหน ทำหน้าเหมือนกับกินข้าวบูดมันเน่ามาทั้งนั้น แถมถ้าจำเป็นต้องส่งกำลังไปเพื่อรักษาหน้า ก็เป็นหลักร้อย ส่วนอาวุธ ส่วนใหญ่ก็เป็นโดรน ไม่มีคนขับ อเมริกาถึงยืนยันว่า no boots on the ground อยู่ตลอดเวลาได้แต่คอยชี้นิ้วสั่ง โอลอง เอ็งไปซิ แคมารอน เอ็งด้วย เอะ แล้วอเมริกาหายไปไหน แค่ส่งไปที่ละร้อย สองร้อยคน แถวซีเรีย อีรัค ขายหน้าพี่เบิ้มหมด
แต่ถึงอย่างนั้น เป็นประเทศมหาอำนาจมา 70 ปี สั่งซ้ายหันขวาหัน ให้มาเลียมือเลียตีนได้หมด แค่ตูดขาดไม่ถึง 10 ปี หมากเด็ด หายหมด หมากรุก ไม่มี อย่างนั้นหรือครับ แบบนี้จะแปลว่าอะไร
แปลว่า อเมริกาซ่อนหมากเด็ด เตรียมไว้รุกฆาต หรือแปลว่าอเมริการบไม่เป็น หรือไม่มีปัญญายกทัพมารบแล้ว…
น่าสังเกตว่า อเมริกาอาจจะถนัดแต่การรบแบบปฏิบัติการ หรือรบแบบกองโจรไปปล้นประเทศที่ไม่ทางสู้มากกว่า หรือไม่ก็ใช้ทหารรับจ้าง ที่เรียกเสียหรูว่า contractor หรือ security advisor เป็นผู้ไป “ดำเนินการ” ไม่ใช่การรบจริง เต็มรูปแบบทางกำลังทหาร
ตลอดเวลาประมาณ 70 ที่ผ่านมา มีเพียง 2,3 ครั้งเท่านั้น ที่เป็นการรบจริง คือ ในสงครามเกาหลี และสงครามเวียตนามเท่านั้น นั่นมันก็กว่า 50 ปีมาแล้ว นอกนั้น มันเป็นการปฏิบัติการโดยพวกทหารรับจ้าง กับทหารนอกระบบ ที่เรียกว่า “stay behind” เครือข่ายหลังฉาก หรือเครือข่ายที่ซ่อนเร้นเกือบทั้งสิ้น แม้ในสมัยสงครามอิรัค อเมริกาก็ใช้ทหารรับจ้างมาก พอๆกับทหารในกองทัพ ถึงได้งบบานฉิบหายไป ส่วนนาโต้เอง ก็ไม่ได้มีกองกำลังทหารจริงทั้งหมด ใช้เครือข่าย stay behind กับ contractor มากเช่นเดียวกัน
แต่ระหว่างเกือบ 10 ที่เศรษฐกิจอเมริกาสะอึก ฝั่งรัสเซียจีน แม้จะไม่ได้ฉลุย แต่ก็น่าจะมีอะไรดี ไม่งั้นรัสเซียคงไม่หาญกล้ายกพลเข้าไปที่ซีเรีย และการยกพลของรัสเซียครั้งนี้ คุณพี่ปูตินเล่นยกมาเป็นกองทัพ ทั้งบกเรืออากาศ มีเรือรบ มีเครื่องบิน มีรถถัง ทหารราบจำนวนแสน
แล้วอเมริกาเดินหมากยังไงครับ ตอนนี้เป็นหมากพูด หรือหมากพ่น อย่าเป็นหมากเผ่นก็แล้วกัน
เมื่อไม่นานมานี่ พณ. ใบตองแห้ง ออกมาพูดเองว่า ไอซิสแผ่วแล้วนะ พื้นที่ที่ยึดไปในอิรัคเหลือน้อยแล้ว ที่ซีเรียก็เช่นเดียวกัน หายไปแยะ ก็ใช่ซิ รัสเซียถล่มเสียราบ กองกำลังร่วมของอเมริกา เข้าไป 4 ปีกว่า ไอซิสมีแต่งอกเพิ่ม รัสเซียมาไม่ถึง 3 เดือน ไอซิสมุดรูหนีออกไปทางลิเบียหมด แต่ พณ.ใบตอง แห้งยังออกมาพูดเอาคะแนน แถมขู่พวกตัวหัวหน้าไอซิสอีกว่า you are next ต่อไปคือพวกเอ็ง ….เป็นการขู่ผ่านสื่อออกทีวี ….เห็นสันดานใบตองแห้งชัดจริงๆ
ตกลงถึงวันนี้ ผมยังไม่เห็นหมากเด็ด หมากรุก อะไรที่จะทำให้ผมเชื่อว่า อเมริกาเป็นนักยุทธศาสตร์ทางด้านการรบ เอาละ มันยังไม่ถึงเวลารบจริง เพราะฉะนั้นตอนนี้ ต้องดูการเดินหมาก “เตรียมรบ” มากกว่า ว่าของใครล้ำลึกเด็ดขาดกว่ากัน คือดูตัวหมาก ที่แต่ละฝ่าย เลือกเอามาเดิน เลือกกิน หรือเลือกทิ้ง
ตามทฤษฏีของไอ้แสบเบรสินสกี้ หมากตัวสำคัญในตะวันออกกลาง มี 2 ตัว คือ อิหร่าน กับตุรกี วันนี้เราเห็นชัดว่า อิหร่าน เปิดเผยว่าอยู่ขั้วรัสเซียจีน แผนบีบด้วยนิวเคลียร์ บีบอิหร่านไม่สำเร็จ
ในตะวันออกกลางจึงเหลือตุรกี ที่เป็นหมากให้ดูว่า รัสเซียเสียตุรกี หรือรัสเซียถีบตุรกีทิ้ง และถ้าอเมริกาเลือกตุรกีมาเป็นหมากฝ่ายตัว เป็นเรื่องดี หรือ ซวยของอเมริกา
ถัดมาเป็นหมาก แถวมหาสมุทรอินเดีย ใกล้บ้านเราเข้ามาหน่อย
ปากีสถาน ก็เป็นหมากที่น่าสนใจตามดูเช่นเดียวกัน ว่า ปากีสถานทิ้งอเมริกา หรืออเมริกาทิ้งปากีสถาน และมาเลือกอินเดีย เพราะหมาก 2 ตัวนี้ คงจะอยู่ข้างเดียวกันยาก แม้ตอนนี้จะมีความพยายาม แต่นั่นแหละ แขกเป็นนักเล่นกล ไม่รู้ว่าอเมริกาจะรู้จักตำนานนี้ไหม
อเมริกา จะเลือกเดินหมากอินเดียเพราะอะไร และอเมริกาได้ หรืออเมริกาเสีย ในการเสียปากีสถาน และ (ยังไม่แน่ว่าจะ) ได้ อินเดีย
ช่วงนี้ดูหมาก 3 ตัวนี้ไว้เท่านั้นแหละครับ ตุรกี ปากีสถาน อืนเดีย การเดินหมาก 3 ตัวนี้ จะทำให้เห็นว่า ยุทธศาตร์ฝ่ายไหน ลึกซึ้ง และฝ่ายใด กำลังเดินหมาก รุก……
หลังปีใหม่ ค่อยมาอ่านนิทานต่อนะครับ
ระหว่างข้ามปี ใช้ชีวิตสบายๆ สวดมนต์ ไหว้พระ ทำบุญ ทำกุศล ถวายพระบาทสมเด็จพระเจ้าอยู่หัว และสมเด็จพระนางเจ้าพระบรมราชินีนาถ ให้เกิดสวัสดิมงคลแก่บ้านเมือง ตัวเองและครอบครัว และโชคดีตลอดปีใหม่ นะครับ
สวัสดีครับ
คนเล่านิทาน
31 ธ.ค. 2558
0 Comments
0 Shares
17 Views
0 Reviews