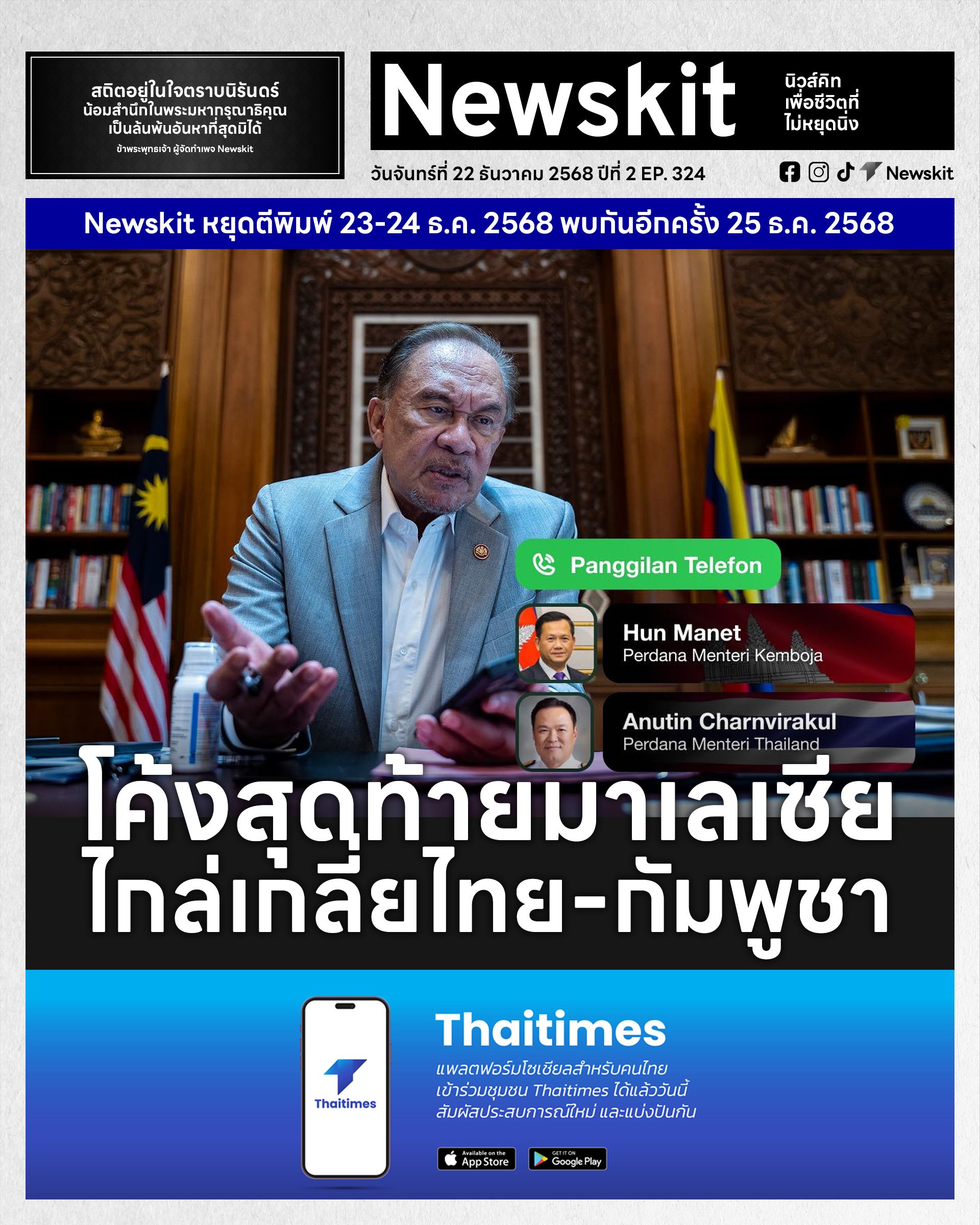
Privacy is Marketing. Anonymity is Architecture: เมื่อคำว่า “ความเป็นส่วนตัว” กลายเป็นสโลแกน แต่ “สถาปัตยกรรม” ต่างหากที่ปกป้องคุณจริง
บทความของ Servury เปิดโปงความจริงที่หลายคนรู้แต่ไม่ค่อยพูดออกมา: คำว่า “เราห่วงใยความเป็นส่วนตัวของคุณ” กลายเป็นเพียง วาทกรรมทางการตลาด ที่บริษัทเทคโนโลยีใช้เพื่อสร้างความเชื่อมั่น ทั้งที่เบื้องหลังระบบยังคงเก็บข้อมูลทุกอย่างที่สามารถระบุตัวตนได้ ตั้งแต่ IP, อีเมล, หมายเลขโทรศัพท์ ไปจนถึงข้อมูลอุปกรณ์และพฤติกรรมการใช้งาน ความเป็นส่วนตัวในโลกปัจจุบันจึงไม่ใช่ “การปกป้องข้อมูล” แต่คือ “การครอบครองข้อมูล” ซึ่งเป็นจุดอ่อนที่พร้อมถูกบังคับ เปิดเผย หรือรั่วไหลได้ทุกเมื่อ
Servury ชี้ให้เห็นความแตกต่างระหว่าง Privacy (ความเป็นส่วนตัว) กับ Anonymity (การไม่ระบุตัวตน) อย่างชัดเจน โดยยกตัวอย่าง Mullvad VPN ที่ถูกตำรวจสวีเดนบุกค้นในปี 2023 แต่ไม่สามารถยึดข้อมูลผู้ใช้ได้ เพราะระบบถูกออกแบบให้ “ไม่มีข้อมูลใดๆ ให้ยึด” ตั้งแต่แรก นี่คือพลังของสถาปัตยกรรมที่ตั้งต้นจากแนวคิด “เก็บให้น้อยที่สุดเท่าที่จำเป็น” ไม่ใช่ “เก็บทุกอย่างแล้วค่อยปกป้องทีหลัง”
Servury นำแนวคิดนี้มาใช้กับแพลตฟอร์มของตัวเอง โดยตัดสินใจไม่เก็บอีเมล ไม่เก็บ IP ไม่เก็บชื่อ ไม่เก็บข้อมูลการใช้งาน และไม่เก็บข้อมูลอุปกรณ์ สิ่งเดียวที่ผู้ใช้มีคือ credential แบบสุ่ม 32 ตัวอักษร ซึ่งเป็นทั้งบัญชีและกุญแจเข้าระบบในเวลาเดียวกัน แน่นอนว่ามันแลกมากับความไม่สะดวก เช่น การกู้บัญชีไม่ได้ แต่ Servury ย้ำว่านี่คือ “ราคาของการไม่ทิ้งร่องรอย” และเป็นสิ่งที่บริษัทอื่นไม่กล้าทำเพราะขัดกับโมเดลธุรกิจที่ต้องพึ่งข้อมูลผู้ใช้
บทความยังเตือนถึง “กับดักอีเมล” ซึ่งเป็นรากเหง้าของการติดตามตัวตนบนอินเทอร์เน็ต เพราะอีเมลผูกกับเบอร์โทร บัตรเครดิต บริการอื่นๆ และสามารถถูกติดตาม วิเคราะห์ หรือ subpoena ย้อนหลังได้ การใช้อีเมลจึงเท่ากับการยอมให้ตัวตนถูกผูกติดกับทุกบริการที่ใช้โดยอัตโนมัติ ในขณะที่โลกกำลังแยกออกเป็นสองฝั่ง—เว็บที่ต้องยืนยันตัวตนทุกอย่าง และ เว็บที่ยังคงรักษาความนิรนาม—บทความนี้คือคำเตือนว่าอนาคตของเสรีภาพออนไลน์ขึ้นอยู่กับสถาปัตยกรรม ไม่ใช่คำโฆษณา
สรุปประเด็นสำคัญ
ความแตกต่างระหว่าง Privacy vs Anonymity
Privacy คือการ “สัญญาว่าจะปกป้องข้อมูล”
Anonymity คือ “ไม่มีข้อมูลให้ปกป้องตั้งแต่แรก”
สถาปัตยกรรมที่ไม่เก็บข้อมูลคือการป้องกันที่แท้จริง
ตัวอย่างจริง: Mullvad VPN
ถูกตำรวจบุกค้นแต่ไม่มีข้อมูลให้ยึด
ใช้ระบบบัญชีแบบตัวเลขสุ่ม 16 หลัก
แสดงให้เห็นว่าการไม่เก็บข้อมูลคือเกราะป้องกันที่แข็งแกร่งที่สุด
สถาปัตยกรรมของ Servury
ไม่เก็บอีเมล ชื่อ IP อุปกรณ์ หรือข้อมูลการใช้งาน
ผู้ใช้มีเพียง credential 32 ตัวอักษร
ไม่มีระบบกู้บัญชี เพราะจะทำลายความนิรนาม
ทำไมอีเมลคือ “ศัตรูของความนิรนาม”
ผูกกับตัวตนจริงในหลายระบบ
ถูกติดตาม วิเคราะห์ และ subpoena ได้
เป็นจุดเริ่มต้นของการเชื่อมโยงตัวตนข้ามบริการ
บริบทโลกอินเทอร์เน็ตยุคใหม่
อินเทอร์เน็ตกำลังแบ่งเป็น “เว็บที่ต้องยืนยันตัวตน” และ “เว็บที่ยังนิรนามได้”
บริการที่ไม่จำเป็นต้องรู้จักผู้ใช้ควรออกแบบให้ไม่เก็บข้อมูล
ความนิรนามคือสถาปัตยกรรม ไม่ใช่ฟีเจอร์
ประเด็นที่ต้องระวัง
สูญเสีย credential = สูญเสียบัญชีถาวร
ความนิรนามไม่เท่ากับความปลอดภัย หากผู้ใช้เก็บ credential ไม่ดี
การไม่เก็บข้อมูลไม่ได้ทำให้ผู้ใช้ “ล่องหน” จากทุกระบบ—เพียงลดการเชื่อมโยงตัวตน
https://servury.com/blog/privacy-is-marketing-anonymity-is-architecture/
บทความของ Servury เปิดโปงความจริงที่หลายคนรู้แต่ไม่ค่อยพูดออกมา: คำว่า “เราห่วงใยความเป็นส่วนตัวของคุณ” กลายเป็นเพียง วาทกรรมทางการตลาด ที่บริษัทเทคโนโลยีใช้เพื่อสร้างความเชื่อมั่น ทั้งที่เบื้องหลังระบบยังคงเก็บข้อมูลทุกอย่างที่สามารถระบุตัวตนได้ ตั้งแต่ IP, อีเมล, หมายเลขโทรศัพท์ ไปจนถึงข้อมูลอุปกรณ์และพฤติกรรมการใช้งาน ความเป็นส่วนตัวในโลกปัจจุบันจึงไม่ใช่ “การปกป้องข้อมูล” แต่คือ “การครอบครองข้อมูล” ซึ่งเป็นจุดอ่อนที่พร้อมถูกบังคับ เปิดเผย หรือรั่วไหลได้ทุกเมื่อ
Servury ชี้ให้เห็นความแตกต่างระหว่าง Privacy (ความเป็นส่วนตัว) กับ Anonymity (การไม่ระบุตัวตน) อย่างชัดเจน โดยยกตัวอย่าง Mullvad VPN ที่ถูกตำรวจสวีเดนบุกค้นในปี 2023 แต่ไม่สามารถยึดข้อมูลผู้ใช้ได้ เพราะระบบถูกออกแบบให้ “ไม่มีข้อมูลใดๆ ให้ยึด” ตั้งแต่แรก นี่คือพลังของสถาปัตยกรรมที่ตั้งต้นจากแนวคิด “เก็บให้น้อยที่สุดเท่าที่จำเป็น” ไม่ใช่ “เก็บทุกอย่างแล้วค่อยปกป้องทีหลัง”
Servury นำแนวคิดนี้มาใช้กับแพลตฟอร์มของตัวเอง โดยตัดสินใจไม่เก็บอีเมล ไม่เก็บ IP ไม่เก็บชื่อ ไม่เก็บข้อมูลการใช้งาน และไม่เก็บข้อมูลอุปกรณ์ สิ่งเดียวที่ผู้ใช้มีคือ credential แบบสุ่ม 32 ตัวอักษร ซึ่งเป็นทั้งบัญชีและกุญแจเข้าระบบในเวลาเดียวกัน แน่นอนว่ามันแลกมากับความไม่สะดวก เช่น การกู้บัญชีไม่ได้ แต่ Servury ย้ำว่านี่คือ “ราคาของการไม่ทิ้งร่องรอย” และเป็นสิ่งที่บริษัทอื่นไม่กล้าทำเพราะขัดกับโมเดลธุรกิจที่ต้องพึ่งข้อมูลผู้ใช้
บทความยังเตือนถึง “กับดักอีเมล” ซึ่งเป็นรากเหง้าของการติดตามตัวตนบนอินเทอร์เน็ต เพราะอีเมลผูกกับเบอร์โทร บัตรเครดิต บริการอื่นๆ และสามารถถูกติดตาม วิเคราะห์ หรือ subpoena ย้อนหลังได้ การใช้อีเมลจึงเท่ากับการยอมให้ตัวตนถูกผูกติดกับทุกบริการที่ใช้โดยอัตโนมัติ ในขณะที่โลกกำลังแยกออกเป็นสองฝั่ง—เว็บที่ต้องยืนยันตัวตนทุกอย่าง และ เว็บที่ยังคงรักษาความนิรนาม—บทความนี้คือคำเตือนว่าอนาคตของเสรีภาพออนไลน์ขึ้นอยู่กับสถาปัตยกรรม ไม่ใช่คำโฆษณา
สรุปประเด็นสำคัญ
ความแตกต่างระหว่าง Privacy vs Anonymity
Privacy คือการ “สัญญาว่าจะปกป้องข้อมูล”
Anonymity คือ “ไม่มีข้อมูลให้ปกป้องตั้งแต่แรก”
สถาปัตยกรรมที่ไม่เก็บข้อมูลคือการป้องกันที่แท้จริง
ตัวอย่างจริง: Mullvad VPN
ถูกตำรวจบุกค้นแต่ไม่มีข้อมูลให้ยึด
ใช้ระบบบัญชีแบบตัวเลขสุ่ม 16 หลัก
แสดงให้เห็นว่าการไม่เก็บข้อมูลคือเกราะป้องกันที่แข็งแกร่งที่สุด
สถาปัตยกรรมของ Servury
ไม่เก็บอีเมล ชื่อ IP อุปกรณ์ หรือข้อมูลการใช้งาน
ผู้ใช้มีเพียง credential 32 ตัวอักษร
ไม่มีระบบกู้บัญชี เพราะจะทำลายความนิรนาม
ทำไมอีเมลคือ “ศัตรูของความนิรนาม”
ผูกกับตัวตนจริงในหลายระบบ
ถูกติดตาม วิเคราะห์ และ subpoena ได้
เป็นจุดเริ่มต้นของการเชื่อมโยงตัวตนข้ามบริการ
บริบทโลกอินเทอร์เน็ตยุคใหม่
อินเทอร์เน็ตกำลังแบ่งเป็น “เว็บที่ต้องยืนยันตัวตน” และ “เว็บที่ยังนิรนามได้”
บริการที่ไม่จำเป็นต้องรู้จักผู้ใช้ควรออกแบบให้ไม่เก็บข้อมูล
ความนิรนามคือสถาปัตยกรรม ไม่ใช่ฟีเจอร์
ประเด็นที่ต้องระวัง
สูญเสีย credential = สูญเสียบัญชีถาวร
ความนิรนามไม่เท่ากับความปลอดภัย หากผู้ใช้เก็บ credential ไม่ดี
การไม่เก็บข้อมูลไม่ได้ทำให้ผู้ใช้ “ล่องหน” จากทุกระบบ—เพียงลดการเชื่อมโยงตัวตน
https://servury.com/blog/privacy-is-marketing-anonymity-is-architecture/
🕶️ Privacy is Marketing. Anonymity is Architecture: เมื่อคำว่า “ความเป็นส่วนตัว” กลายเป็นสโลแกน แต่ “สถาปัตยกรรม” ต่างหากที่ปกป้องคุณจริง
บทความของ Servury เปิดโปงความจริงที่หลายคนรู้แต่ไม่ค่อยพูดออกมา: คำว่า “เราห่วงใยความเป็นส่วนตัวของคุณ” กลายเป็นเพียง วาทกรรมทางการตลาด ที่บริษัทเทคโนโลยีใช้เพื่อสร้างความเชื่อมั่น ทั้งที่เบื้องหลังระบบยังคงเก็บข้อมูลทุกอย่างที่สามารถระบุตัวตนได้ ตั้งแต่ IP, อีเมล, หมายเลขโทรศัพท์ ไปจนถึงข้อมูลอุปกรณ์และพฤติกรรมการใช้งาน ความเป็นส่วนตัวในโลกปัจจุบันจึงไม่ใช่ “การปกป้องข้อมูล” แต่คือ “การครอบครองข้อมูล” ซึ่งเป็นจุดอ่อนที่พร้อมถูกบังคับ เปิดเผย หรือรั่วไหลได้ทุกเมื่อ
Servury ชี้ให้เห็นความแตกต่างระหว่าง Privacy (ความเป็นส่วนตัว) กับ Anonymity (การไม่ระบุตัวตน) อย่างชัดเจน โดยยกตัวอย่าง Mullvad VPN ที่ถูกตำรวจสวีเดนบุกค้นในปี 2023 แต่ไม่สามารถยึดข้อมูลผู้ใช้ได้ เพราะระบบถูกออกแบบให้ “ไม่มีข้อมูลใดๆ ให้ยึด” ตั้งแต่แรก นี่คือพลังของสถาปัตยกรรมที่ตั้งต้นจากแนวคิด “เก็บให้น้อยที่สุดเท่าที่จำเป็น” ไม่ใช่ “เก็บทุกอย่างแล้วค่อยปกป้องทีหลัง”
Servury นำแนวคิดนี้มาใช้กับแพลตฟอร์มของตัวเอง โดยตัดสินใจไม่เก็บอีเมล ไม่เก็บ IP ไม่เก็บชื่อ ไม่เก็บข้อมูลการใช้งาน และไม่เก็บข้อมูลอุปกรณ์ สิ่งเดียวที่ผู้ใช้มีคือ credential แบบสุ่ม 32 ตัวอักษร ซึ่งเป็นทั้งบัญชีและกุญแจเข้าระบบในเวลาเดียวกัน แน่นอนว่ามันแลกมากับความไม่สะดวก เช่น การกู้บัญชีไม่ได้ แต่ Servury ย้ำว่านี่คือ “ราคาของการไม่ทิ้งร่องรอย” และเป็นสิ่งที่บริษัทอื่นไม่กล้าทำเพราะขัดกับโมเดลธุรกิจที่ต้องพึ่งข้อมูลผู้ใช้
บทความยังเตือนถึง “กับดักอีเมล” ซึ่งเป็นรากเหง้าของการติดตามตัวตนบนอินเทอร์เน็ต เพราะอีเมลผูกกับเบอร์โทร บัตรเครดิต บริการอื่นๆ และสามารถถูกติดตาม วิเคราะห์ หรือ subpoena ย้อนหลังได้ การใช้อีเมลจึงเท่ากับการยอมให้ตัวตนถูกผูกติดกับทุกบริการที่ใช้โดยอัตโนมัติ ในขณะที่โลกกำลังแยกออกเป็นสองฝั่ง—เว็บที่ต้องยืนยันตัวตนทุกอย่าง และ เว็บที่ยังคงรักษาความนิรนาม—บทความนี้คือคำเตือนว่าอนาคตของเสรีภาพออนไลน์ขึ้นอยู่กับสถาปัตยกรรม ไม่ใช่คำโฆษณา
📌 สรุปประเด็นสำคัญ
✅ ความแตกต่างระหว่าง Privacy vs Anonymity
➡️ Privacy คือการ “สัญญาว่าจะปกป้องข้อมูล”
➡️ Anonymity คือ “ไม่มีข้อมูลให้ปกป้องตั้งแต่แรก”
➡️ สถาปัตยกรรมที่ไม่เก็บข้อมูลคือการป้องกันที่แท้จริง
✅ ตัวอย่างจริง: Mullvad VPN
➡️ ถูกตำรวจบุกค้นแต่ไม่มีข้อมูลให้ยึด
➡️ ใช้ระบบบัญชีแบบตัวเลขสุ่ม 16 หลัก
➡️ แสดงให้เห็นว่าการไม่เก็บข้อมูลคือเกราะป้องกันที่แข็งแกร่งที่สุด
✅ สถาปัตยกรรมของ Servury
➡️ ไม่เก็บอีเมล ชื่อ IP อุปกรณ์ หรือข้อมูลการใช้งาน
➡️ ผู้ใช้มีเพียง credential 32 ตัวอักษร
➡️ ไม่มีระบบกู้บัญชี เพราะจะทำลายความนิรนาม
✅ ทำไมอีเมลคือ “ศัตรูของความนิรนาม”
➡️ ผูกกับตัวตนจริงในหลายระบบ
➡️ ถูกติดตาม วิเคราะห์ และ subpoena ได้
➡️ เป็นจุดเริ่มต้นของการเชื่อมโยงตัวตนข้ามบริการ
✅ บริบทโลกอินเทอร์เน็ตยุคใหม่
➡️ อินเทอร์เน็ตกำลังแบ่งเป็น “เว็บที่ต้องยืนยันตัวตน” และ “เว็บที่ยังนิรนามได้”
➡️ บริการที่ไม่จำเป็นต้องรู้จักผู้ใช้ควรออกแบบให้ไม่เก็บข้อมูล
➡️ ความนิรนามคือสถาปัตยกรรม ไม่ใช่ฟีเจอร์
‼️ ประเด็นที่ต้องระวัง
⛔ สูญเสีย credential = สูญเสียบัญชีถาวร
⛔ ความนิรนามไม่เท่ากับความปลอดภัย หากผู้ใช้เก็บ credential ไม่ดี
⛔ การไม่เก็บข้อมูลไม่ได้ทำให้ผู้ใช้ “ล่องหน” จากทุกระบบ—เพียงลดการเชื่อมโยงตัวตน
https://servury.com/blog/privacy-is-marketing-anonymity-is-architecture/
0 ความคิดเห็น
0 การแบ่งปัน
43 มุมมอง
0 รีวิว