🩷 รวมข่าวจากเวบ TechRadar 🩷
#รวมข่าวIT #20251216 #TechRadar LG เปิดตัวทีวี Micro RGB evo ที่ CES 2026
LG กำลังสร้างความฮือฮาในงาน CES 2026 ด้วยการเปิดตัวทีวีรุ่นใหม่ที่ใช้เทคโนโลยี Micro RGB evo ซึ่งเปลี่ยนหลอดไฟ LED แบบเดิมไปเป็นหลอดไฟสีแดง เขียว และน้ำเงินขนาดจิ๋ว เพื่อควบคุมแสงและสีได้ละเอียดขึ้น ผลลัพธ์คือภาพที่สว่างสดใสและสีสันจัดเต็มใกล้เคียง OLED แต่ยังคงความสว่างสูงของ LCD จุดเด่นคือการครอบคลุมสีครบทั้ง BT.2020, DCI-P3 และ Adobe RGB พร้อมระบบประมวลผล α11 AI Gen 3 ที่ช่วยอัปสเกลภาพให้คมชัดขึ้น ถือเป็นการพยายามปิดช่องว่างระหว่าง LCD และ OLED ที่น่าสนใจมากสำหรับคนรักภาพคมชัดและสีสดใส
https://www.techradar.com/televisions/lg-reveals-micro-rgb-evo-tv-with-bold-claims-of-perfect-color Netflix เลิกใช้ Google Cast แต่ Apple TV บน Android นำกลับมาอีกครั้ง
Netflix เคยยกเลิกฟีเจอร์ Google Cast ที่ให้ผู้ใช้ส่งภาพจากมือถือขึ้นจอทีวี แต่ล่าสุด Apple TV บน Android กลับนำฟีเจอร์นี้กลับมา ทำให้ผู้ใช้สามารถสตรีมคอนเทนต์จากมือถือไปยังทีวีได้อีกครั้ง การเคลื่อนไหวนี้สะท้อนถึงการแข่งขันในตลาดสตรีมมิ่งที่ยังคงดุเดือด และการที่ Apple พยายามทำให้บริการของตนเข้าถึงผู้ใช้ Android ได้สะดวกขึ้น
https://www.techradar.com/streaming/apple-tv-plus/netflix-dropped-google-cast-now-apple-tv-for-android-just-brought-it-back NAS พกพาใส่ SSD 4 ตัว พร้อมพลัง Intel N150
มีการเปิดตัวอุปกรณ์ NAS ขนาดเล็กที่ดูเหมือนวิทยุทรานซิสเตอร์เก่า แต่ภายในบรรจุ SSD ได้ถึง 4 ตัว ใช้พลังจาก Intel N150 และมีพอร์ต LAN 2.5Gb สองช่อง รวมถึง RAM 12GB จุดขายคือความสามารถในการพกพาและเก็บข้อมูลได้มาก แต่ก็มีค่าใช้จ่ายแฝงที่อาจเกินความคาดหมาย เหมาะสำหรับคนที่ต้องการระบบจัดเก็บข้อมูลที่คล่องตัวและมีสไตล์ไม่เหมือนใคร
https://www.techradar.com/pro/is-that-your-grandads-transistor-radio-no-its-a-4-ssd-nas-with-two-2-5gb-lan-ports-12gb-ram-and-a-cracking-name-the-orange-colored-youyeetoo-nestdisk นักพัฒนาสร้างกล่องสำรองข้อมูล iPhone แบบออฟไลน์
นักพัฒนารายหนึ่งได้สร้างอุปกรณ์สำรองข้อมูล iPhone ที่ไม่ต้องพึ่งพาคลาวด์ แต่ใช้การเชื่อมต่อผ่าน USB และเข้ารหัสข้อมูลเพื่อเก็บไว้ในเครื่องโดยตรง ถือเป็นทางเลือกใหม่สำหรับคนที่ไม่อยากจ่ายค่าบริการ iCloud หรือกังวลเรื่องความปลอดภัยของข้อมูลบนคลาวด์ แม้จะยังไม่เหมาะกับผู้ใช้ทั่วไป แต่แนวคิดนี้สะท้อนถึงความต้องการควบคุมข้อมูลส่วนตัวมากขึ้น
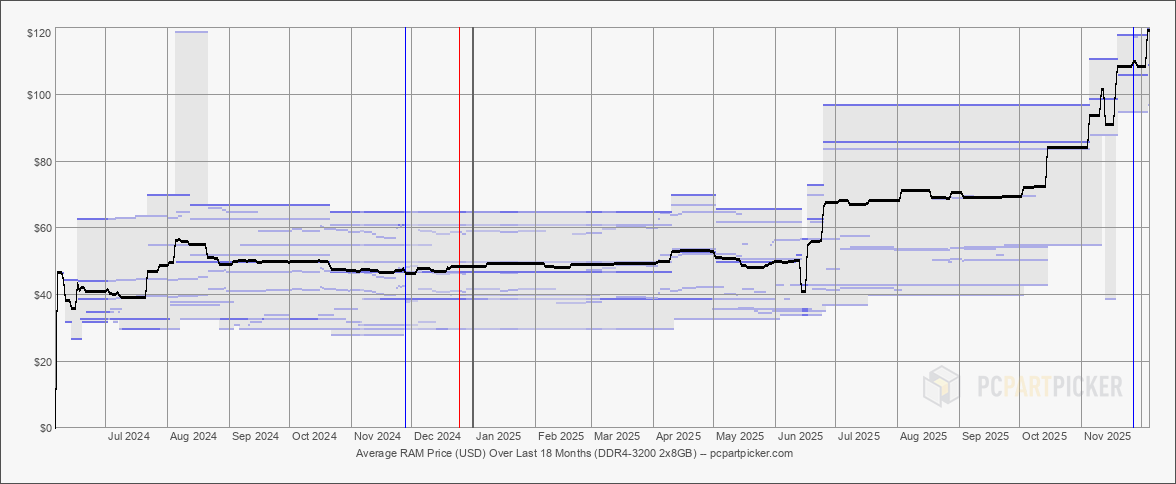
https://www.techradar.com/pro/want-to-back-up-your-iphone-securely-without-paying-the-apple-tax-theres-a-hack-for-that-but-it-isnt-for-everyone-yet วิกฤติ RAM อาจกระทบหนักต่อโน้ตบุ๊กเกมมิ่ง
ตลาดโน้ตบุ๊กเกมมิ่งกำลังเผชิญปัญหาวิกฤติ RAM ที่อาจทำให้เครื่องเล่นเกมประสิทธิภาพสูงมีราคาสูงขึ้นและหายากขึ้น เหตุผลมาจากความต้องการหน่วยความจำที่เพิ่มขึ้นทั่วโลก ทั้งจาก AI และการประมวลผลข้อมูลขนาดใหญ่ ส่งผลให้ผู้ผลิตโน้ตบุ๊กเกมมิ่งต้องปรับตัวและอาจทำให้ผู้เล่นเกมต้องจ่ายแพงกว่าเดิมเพื่อได้เครื่องที่แรงพอ
https://www.techradar.com/computing/memory/the-ram-crisis-will-be-a-disaster-for-gaming-laptops-heres-why Slop: คำแห่งปีที่สะท้อนอินเทอร์เน็ตเต็มไปด้วยขยะดิจิทัล
ปีนี้ Merriam-Webster เลือกคำว่า “Slop” เป็น Word of the Year 2025 เพื่ออธิบายเนื้อหาดิจิทัลคุณภาพต่ำที่ถูกผลิตขึ้นอย่างมหาศาลด้วย AI ไม่ว่าจะเป็นบทความ ภาพ วิดีโอ หรือพอดแคสต์ หลายอย่างดูเหมือนจะสร้างได้ง่ายแต่กลับทำให้โลกออนไลน์เต็มไปด้วยสิ่งที่คนเรียกว่า “AI slop” จนยากจะแยกออกว่าอะไรคือผลงานมนุษย์จริงๆ และอะไรคือสิ่งที่เครื่องจักรสร้างขึ้นมา เรื่องนี้สะท้อนว่าพลังของเครื่องมือ AI ถูกส่งถึงมือผู้ใช้เร็วเกินไปโดยที่ยังไม่ทันคิดถึงผลกระทบ ทำให้เราต้องเผชิญกับทะเลข้อมูลที่ปะปนทั้งคุณภาพและขยะไปพร้อมกัน
https://www.techradar.com/ai-platforms-assistants/we-filled-the-internet-with-garbage-and-now-slop-is-the-word-of-the-year-nice-going-ai Super X: แท็บเล็ตลูกผสมที่แรงระดับเดสก์ท็อป
OneXPlayer เปิดตัว Super X อุปกรณ์ลูกผสมที่รวมแท็บเล็ตกับพลังการประมวลผลระดับเดสก์ท็อป หน้าจอใหญ่ถึง 14 นิ้ว มาพร้อมซีพียู 16 คอร์ GPU ระดับ 5060-class และ RAM สูงสุด 128GB จุดเด่นคือการออกแบบระบบระบายความร้อนด้วยน้ำ ทำให้เครื่องเล็กแต่ยังคงประสิทธิภาพสูง เหมาะกับคนที่อยากได้ความแรงแบบ PC แต่ยังพกพาได้สะดวก แม้ราคาคาดว่าจะไม่ต่ำกว่า 2000 ดอลลาร์ แต่ถือเป็นการยกระดับแท็บเล็ตให้ก้าวไปอีกขั้น
https://www.techradar.com/pro/a-water-cooled-amd-ai-14-inch-tablet-with-16-cpu-cores-a-5060-class-gpu-and-128gb-ram-is-exactly-what-i-need-for-christmas-i-dont-think-it-will-cost-less-than-usd2000-though SSD จิ๋วแต่แรง: Samsung เปิดตัว PCIe Gen5 รุ่นใหม่
Samsung เผยโฉม SSD รุ่น PM9E1 ที่มาในขนาดเล็กเพียง 22 x 42 มม. แต่รองรับมาตรฐาน PCIe Gen5 ทำให้ได้ความเร็วสูงและความจุที่จริงจัง แม้จะมาแบบเงียบๆ แต่ถือเป็นการขยายตลาดสู่กลุ่มผู้ใช้ที่ต้องการอุปกรณ์เก็บข้อมูลขนาดเล็กแต่ไม่ลดทอนประสิทธิภาพ เหมาะกับโน้ตบุ๊กหรืออุปกรณ์พกพาที่ต้องการความเร็วระดับสูงสุดในพื้นที่จำกัด
https://www.techradar.com/pro/samsungs-surprising-stealth-superfast-ssd-surfaces-silently-pm9e1-turns-out-to-be-a-mini-9100-pro-measuring-just-22-x-42mm-with-pcie-gen5-capabilities DoomScroll: เว็บไซต์ใหม่รวมแผนที่ Doom แบบไม่รู้จบ
แฟนเกม Doom ได้เฮ เมื่อมีเว็บไซต์ใหม่ชื่อ DoomScroll ที่รวบรวมแผนที่เกม Doom ไว้ให้เลือกเล่นได้ไม่รู้จบผ่านเบราว์เซอร์ ผู้เล่นสามารถเข้าไปเลือกแผนที่ที่ชอบแล้วเล่นได้ทันที ถือเป็นการเปิดคลังเกมคลาสสิกให้เข้าถึงง่ายขึ้น และยังทำให้ชุมชนผู้เล่นสามารถแชร์ผลงานกันได้สะดวกขึ้นด้วย
https://www.techradar.com/gaming/pc-gaming/new-doomscroll-website-is-an-endless-library-of-doom-maps-you-can-pick-from-and-play-in-your-browser หน่วยความจำแห่งอนาคต: Kioxia พัฒนา 3D DRAM
Kioxia ประกาศความสำเร็จในการพัฒนาเทคโนโลยี 3D DRAM โดยใช้ stacked oxide-semiconductors ซึ่งช่วยลดต้นทุนการผลิตและเพิ่มความหนาแน่นของหน่วยความจำ แม้จะยังไม่พร้อมสู่ตลาดผู้บริโภคในทันที แต่ถือเป็นก้าวสำคัญที่จะเปลี่ยนโฉมอุตสาหกรรมหน่วยความจำในทศวรรษหน้า ทำให้คาดหวังได้ว่าอนาคตเราจะได้เห็น RAM ที่เร็วขึ้นและราคาถูกลง
https://www.techradar.com/pro/crying-over-expensive-ram-kioxia-may-have-cracked-the-3d-ram-puzzle-paving-the-way-for-cheaper-faster-memory-but-it-probably-wont-reach-the-market-till-the-next-decade Apple อุดช่องโหว่ Zero-Day สุดอันตราย
Apple ออกแพตช์แก้ไขช่องโหว่ร้ายแรงใน WebKit ที่ถูกใช้โจมตีแบบเจาะจงบุคคลระดับสูง โดยช่องโหว่นี้อาจเปิดทางให้แฮกเกอร์เข้าควบคุมเครื่องจากระยะไกลได้ ทีม Google TAG และ Apple ร่วมกันค้นพบและแก้ไข ซึ่งถือเป็นการทำงานร่วมกันที่ไม่ค่อยเกิดขึ้นบ่อยนัก การอัปเดตครอบคลุมทั้ง iOS, iPadOS, macOS, watchOS, tvOS, visionOS และ Safari ผู้ใช้ทั่วไปแม้จะไม่ใช่เป้าหมายหลัก แต่ก็ถูกแนะนำให้รีบอัปเดตเพื่อความปลอดภัยทันที
https://www.techradar.com/pro/security/apple-says-it-fixed-zero-day-flaws-used-for-sophisticated-attacks CEO Windscribe วิจารณ์การแบน VPN สำหรับเด็ก
Windscribe ผู้ให้บริการ VPN ออกมาแสดงความเห็นว่าการห้ามเด็กใช้ VPN เป็น “วิธีแก้ที่แย่ที่สุด” เพราะ VPN ไม่ใช่เครื่องมืออันตราย แต่กลับเป็นสิ่งที่ช่วยปกป้องความเป็นส่วนตัวและความปลอดภัย การแบนอาจทำให้เด็กขาดโอกาสในการเรียนรู้การใช้งานอินเทอร์เน็ตอย่างปลอดภัย และยังไม่แก้ปัญหาที่แท้จริงของการใช้งานออนไลน์
https://www.techradar.com/vpn/vpn-privacy-security/banning-vpns-for-kids-is-the-dumbest-possible-fix-windscribe-ceo กล้องวงจรปิดแบตเตอรี่ไร้ขีดจำกัด
มีการเปิดตัวกล้องวงจรปิดรุ่นใหม่ที่ชูจุดขายเรื่อง “แบตเตอรี่ไม่จำกัด” สามารถทำงานได้ตลอด 24 ชั่วโมงโดยไม่ต้องกังวลเรื่องการชาร์จบ่อย ๆ ราคาก็ไม่สูงอย่างที่คิด ทำให้ผู้ใช้ทั่วไปสามารถเข้าถึงได้ง่ายขึ้น กล้องนี้เหมาะสำหรับผู้ที่ต้องการความปลอดภัยต่อเนื่องโดยไม่ต้องยุ่งยากกับการบำรุงรักษาแบตเตอรี่
https://www.techradar.com/home/smart-home/this-home-security-cam-monitors-your-property-24-7-with-unlimited-battery-life-and-it-costs-less-than-you-might-expect Garmin เผลอหลุดข้อมูล Vivosmart 6
Garmin มีข่าวหลุดเกี่ยวกับสมาร์ทแทร็กเกอร์รุ่นใหม่ Vivosmart 6 ที่คาดว่าจะมาพร้อมการอัปเกรดสำคัญเหนือรุ่นก่อน แม้ยังไม่มีรายละเอียดเต็ม แต่คาดว่าจะมีฟีเจอร์ด้านสุขภาพและการติดตามการออกกำลังกายที่แม่นยำขึ้น การหลุดครั้งนี้สร้างความตื่นเต้นให้กับผู้ที่ติดตามอุปกรณ์สวมใส่ของ Garmin อยู่แล้ว
https://www.techradar.com/health-fitness/fitness-trackers/garmin-just-leaked-its-vivosmart-6-tracker-and-it-might-come-with-one-major-upgrade-over-its-predecessor แอป Freedom Chat ทำข้อมูลผู้ใช้หลุด
มีรายงานว่าแอปแชทชื่อ Freedom Chat เผยข้อมูลผู้ใช้โดยไม่ได้ตั้งใจ ทั้งหมายเลขโทรศัพท์และรายละเอียดอื่น ๆ ทำให้เกิดความกังวลเรื่องความปลอดภัยและความเป็นส่วนตัวของผู้ใช้ แอปนี้ถูกวิจารณ์อย่างหนักว่าขาดมาตรการป้องกันที่รัดกุม และอาจทำให้ผู้ใช้เสี่ยงต่อการถูกโจมตีหรือการละเมิดข้อมูล
https://www.techradar.com/pro/security/messaging-app-freedom-chat-exposes-user-phone-numbers-and-more-heres-what-we-know Google เปิดฟีเจอร์แปลสดผ่านหูฟัง
Google กำลังยกระดับการสื่อสารข้ามภาษาให้ก้าวไปอีกขั้น ด้วยการเปิดตัวฟีเจอร์ “Live Translation” ที่สามารถใช้งานได้กับหูฟังทุกยี่ห้อ ไม่จำกัดเฉพาะ Pixel Buds อีกต่อไป โดยเริ่มทดสอบในสหรัฐฯ เม็กซิโก และอินเดีย ฟีเจอร์นี้ไม่เพียงแค่แปลคำต่อคำ แต่ยังรักษาน้ำเสียง จังหวะ และอารมณ์ของผู้พูด ทำให้การสนทนาเป็นธรรมชาติมากขึ้น นอกจากนี้ Google ยังปรับปรุงระบบ Gemini ให้เข้าใจสำนวนและภาษาพูด เช่น “stealing my thunder” ที่ไม่สามารถแปลตรงตัวได้ พร้อมทั้งเพิ่มเครื่องมือช่วยเรียนภาษา เช่น การให้คำแนะนำด้านการออกเสียง และระบบติดตามความก้าวหน้า ฟีเจอร์นี้รองรับกว่า 70 ภาษา และมีแผนจะขยายไปยัง iOS ในปี 2026
https://www.techradar.com/computing/software/google-smashes-language-barriers-with-live-translation-for-any-earbuds-on-android-heres-how-it-works อีเมลไม่ใช่จุดอ่อน แต่การตั้งค่าคลาวด์ต่างหาก
หลายครั้งที่เกิดเหตุข้อมูลรั่วไหล อีเมลมักถูกมองว่าเป็นตัวการ แต่จริง ๆ แล้วปัญหามาจากการตั้งค่าคลาวด์ที่ผิดพลาดมากกว่า กว่า 99% ของความล้มเหลวด้านความปลอดภัยเกิดจากผู้ใช้เอง เช่น คลิกลิงก์ฟิชชิ่ง ใช้รหัสผ่านซ้ำ หรือจัดการข้อมูลผิดพลาด การโทษอีเมลจึงเป็นการเบี่ยงเบนความสนใจไปจากต้นเหตุที่แท้จริง ผู้เชี่ยวชาญแนะนำว่าการป้องกันควรเริ่มจากการเข้ารหัสข้อมูล การเสริมความปลอดภัยของระบบปฏิบัติการ และการฝึกอบรมผู้ใช้ให้รู้เท่าทันภัยไซเบอร์ เมื่อผู้ใช้มีความรู้และระบบถูกเข้ารหัสอย่างดี อีเมลก็จะกลายเป็นพื้นที่ที่ปลอดภัยและมีประสิทธิภาพมากขึ้น
https://www.techradar.com/pro/your-email-app-isnt-the-weak-link-but-your-cloud-configuration-probably-is Microsoft ขยายโครงการ Bug Bounty
Microsoft ประกาศปรับโครงการ Bug Bounty ครั้งใหญ่ เปิดให้ผู้เชี่ยวชาญด้านความปลอดภัยสามารถส่งรายงานช่องโหว่ได้ครอบคลุมทุกผลิตภัณฑ์และบริการ แม้บางโปรแกรมจะไม่มีการตั้งค่ารางวัลอย่างเป็นทางการก็ตาม แนวทางใหม่นี้เรียกว่า “In Scope by Default” ซึ่งหมายความว่าหากช่องโหว่มีผลกระทบต่อบริการออนไลน์ของ Microsoft ก็จะได้รับเงินรางวัลตามระดับความรุนแรง โดยปีที่ผ่านมา Microsoft จ่ายเงินรางวัลไปกว่า 17 ล้านดอลลาร์ มากกว่า Google ที่จ่ายราว 11.8 ล้านดอลลาร์ การขยายนี้ครอบคลุมทั้งโค้ดของ Microsoft โค้ดจากบุคคลที่สาม และโอเพ่นซอร์ส ถือเป็นการสร้างแรงจูงใจให้ผู้เชี่ยวชาญช่วยตรวจสอบความปลอดภัยในวงกว้างยิ่งขึ้น
https://www.techradar.com/pro/security/microsoft-will-expand-bug-bounties-even-on-programs-without-official-payouts Oracle ทุ่มมหาศาลกับดีลศูนย์ข้อมูล
Oracle กำลังเดินเกมครั้งใหญ่ในโลกคลาวด์และศูนย์ข้อมูล ล่าสุดมีการเปิดเผยว่าได้ทำสัญญาเช่าศูนย์ข้อมูลและคลาวด์รวมมูลค่าถึง 248 พันล้านดอลลาร์ ซึ่งจะทยอยเริ่มใช้ตั้งแต่ปี 2026 ไปจนถึง 2028 และกินเวลายาวนานถึง 15–19 ปี การขยายตัวนี้เกิดจากความต้องการที่เพิ่มขึ้นอย่างต่อเนื่อง ทั้งจากลูกค้าใหญ่ ๆ อย่าง Meta, Nvidia และ OpenAI ที่เพิ่งเซ็นสัญญาเพิ่มอีก 300 พันล้านดอลลาร์ ทำให้ Oracle ต้องเพิ่มกำลังการผลิตไฟฟ้าและลงทุนเพิ่มหนี้อีกหลายหมื่นล้าน แม้จะเป็นภาระ แต่ก็สะท้อนว่าบริษัทกำลังเดิมพันอนาคตไว้กับการเติบโตของตลาด AI และคลาวด์อย่างเต็มที่
https://www.techradar.com/pro/oracle-reportedly-signs-major-huge-cloud-data-center-deals-in-the-last-quarter-nearly-usd250-billion-in-new-commitments-revealed ChatGPT 5.2 vs Gemini 3
มีการทดสอบเปรียบเทียบสองแชตบอทที่โด่งดังที่สุดในโลกตอนนี้ คือ ChatGPT 5.2 และ Gemini 3 ผู้เขียนลองใช้งานจริงเพื่อดูว่าใครตอบโจทย์ได้ดีกว่า ผลลัพธ์ออกมาน่าสนใจเพราะแต่ละตัวมีจุดแข็งต่างกัน ChatGPT 5.2 โดดเด่นเรื่องการให้คำตอบที่ละเอียดและมีความคิดเชิงลึก ส่วน Gemini 3 เน้นความเร็วและความกระชับในการสื่อสาร การแข่งขันนี้สะท้อนว่าตลาด AI กำลังร้อนแรง และผู้ใช้ก็มีทางเลือกมากขึ้นตามสไตล์ที่ต้องการ
https://www.techradar.com/ai-platforms-assistants/chatgpt/chatgpt-5-2-vs-gemini-3-i-tried-the-worlds-most-popular-chatbots-to-see-which-is-best-and-the-result-might-surprise-you โลกเสมือนที่มีหัวใจมนุษย์
เรื่องราวของ Victoria Fard ศิลปินที่ใช้พลังของคอมพิวเตอร์ที่ขับเคลื่อนด้วย Snapdragon สร้างโลกเสมือนที่เต็มไปด้วยความรู้สึกและความเป็นมนุษย์ เธอไม่ได้มองเทคโนโลยีเป็นเพียงเครื่องมือ แต่ใช้มันเพื่อถ่ายทอดความทรงจำ ความรู้สึก และเรื่องราวที่เชื่อมโยงผู้คนเข้าด้วยกัน ผลงานของเธอจึงไม่ใช่แค่ภาพสวย ๆ แต่เป็นการสร้างพื้นที่ที่ผู้คนสามารถสัมผัสความเป็นมนุษย์ผ่านโลกดิจิทัลได้อย่างลึกซึ้ง
https://www.techradar.com/tech/memories-in-pixel-how-victoria-fard-uses-a-pc-powered-by-snapdragon-to-build-worlds-that-are-deeply-human ซีอีโอยังเดินหน้าลงทุน AI แม้ผลลัพธ์ไม่ชัด
แม้หลายบริษัทจะยังไม่เห็นผลลัพธ์ที่ชัดเจนจากการลงทุนใน AI แต่ซีอีโอจำนวนมากก็ยังคงเดินหน้าทุ่มงบต่อไป เหตุผลคือพวกเขามองว่า AI เป็นเทคโนโลยีที่ไม่สามารถมองข้ามได้ และหากหยุดลงทุนอาจเสียโอกาสในอนาคต ถึงแม้จะมีความเสี่ยงและความไม่แน่นอน แต่การตัดสินใจนี้สะท้อนถึงความเชื่อมั่นว่าการลงทุนใน AI จะเป็นกุญแจสำคัญในการแข่งขันระยะยาว
https://www.techradar.com/pro/ceos-seem-determined-to-keep-spending-on-ai-despite-mixed-success ศาลรัสเซียสั่งอายัดทรัพย์ Google ในฝรั่งเศส
มีข่าวใหญ่จากยุโรป เมื่อศาลรัสเซียมีคำสั่งให้อายัดทรัพย์สินของ Google ในฝรั่งเศสมูลค่ากว่า 129 ล้านดอลลาร์ สาเหตุเกี่ยวข้องกับข้อพิพาททางกฎหมายและการดำเนินธุรกิจที่ซับซ้อนในหลายประเทศ เหตุการณ์นี้สะท้อนถึงแรงกดดันที่บริษัทยักษ์ใหญ่ด้านเทคโนโลยีต้องเผชิญในระดับโลก ทั้งจากกฎระเบียบและความขัดแย้งทางการเมืองที่ส่งผลต่อการดำเนินงาน
https://www.techradar.com/pro/security/russian-court-ruling-could-see-usd129-million-freeze-on-some-of-googles-french-assets Microsoft เจอศึกใหญ่เรื่อง Cloud Licensing ในสหราชอาณาจักร
เรื่องนี้เริ่มจากการที่ Microsoft ถูกกล่าวหาว่ากำหนดเงื่อนไขการใช้งาน Windows Server บน Cloud ของคู่แข่งอย่าง AWS และ Google Cloud ให้ยุ่งยากและมีค่าใช้จ่ายสูง จนทำให้หลายองค์กรในสหราชอาณาจักรเสียเงินไปเป็นจำนวนมาก คดีนี้ถูกยื่นต่อศาล Competition Appeal Tribunal โดยมีองค์กรกว่า 59,000 แห่งเข้าร่วมเป็นกลุ่มฟ้องร้อง หาก Microsoft ถูกตัดสินว่าผิดจริง อาจต้องจ่ายค่าชดเชยสูงถึง 2 พันล้านปอนด์ ขณะที่ Microsoft ยืนยันว่าเป็นเพียงการกล่าวหาเกินจริงจากกลุ่มทนายและผู้สนับสนุน แต่แรงกดดันก็ยังคงมีต่อเนื่อง เพราะ Google เองก็เคยร้องเรียนเรื่องนี้ต่อ EU มาก่อนแล้ว
https://www.techradar.com/pro/microsoft-is-back-in-court-in-the-uk-over-unfair-cloud-licensing-claims UGreen เปิดตัว eGPU Dock ท้าชน Razer ในตลาด eGPU ที่กำลังร้อนแรง
UGreen ได้เปิดตัว Linkstation eGPU Dock ที่มาพร้อมพลังงานในตัวถึง 850W และพอร์ตเชื่อมต่อใหม่อย่าง Oculink และ USB4 จุดเด่นคือราคาประมาณ 325 ดอลลาร์ ซึ่งใกล้เคียงกับ Razer Core X V2 แต่เหนือกว่าตรงที่มี PSU ในตัวและรองรับการ์ดจอขนาดใหญ่ถึง 370 มม. อย่างไรก็ตาม ดีไซน์ของ UGreen ยังเปิดโล่งมากกว่า Razer ที่มีโครงสร้างปิด ทำให้บางคนกังวลเรื่องความปลอดภัยของการ์ดจอ ถึงอย่างนั้น นี่ก็ถือเป็นการก้าวเข้าสู่ตลาดใหม่ที่น่าจับตามองของ UGreen ที่เดิมทำอุปกรณ์เสริมอย่าง Dock และ Charger
https://www.techradar.com/computing/gpu/its-a-great-time-to-buy-an-egpu-and-ugreens-new-razer-rival-has-two-major-tricks-up-its-sleeve วิกฤติ RAM อาจทำให้สมาร์ทโฟนถอยหลังในปี 2026
นักวิเคราะห์เตือนว่าความต้องการ RAM ที่สูงขึ้นจากศูนย์ข้อมูล AI กำลังทำให้ราคาพุ่งขึ้น ส่งผลให้ผู้ผลิตสมาร์ทโฟนอาจต้องลดสเปกลง แทนที่จะเพิ่ม RAM เป็น 16GB ในรุ่นเรือธงใหม่ อาจยังคงอยู่ที่ 12GB หรือบางรุ่นอาจลดลงเหลือ 8GB สำหรับรุ่นกลาง และ 4GB สำหรับรุ่นล่าง ทั้งนี้แม้จะเป็นการคาดการณ์ แต่ก็มีความเป็นไปได้สูง เพราะตลาด AI กำลังดูดซับทรัพยากรไปอย่างมหาศาล ซึ่งอาจย้อนแย้งกับการพัฒนา AI บนมือถือที่ต้องใช้ RAM มากเช่นกัน
https://www.techradar.com/phones/the-ram-crisis-will-see-smartphone-specs-go-backwards-in-2026-experts-warn-heres-why Apple ควรทำ Smart Ring เพื่อแก้ปัญหาความยุ่งยากของ Smartwatch
ผู้เขียนเล่าประสบการณ์ตรงว่าแม้ Apple Watch จะมีฟีเจอร์ด้านสุขภาพและการออกกำลังกายที่ยอดเยี่ยม แต่ก็สร้างความลำบากใจเพราะเขาเป็นคนรักนาฬิกากลไกและไม่อยากละทิ้งการใส่นาฬิกาแบบดั้งเดิม จนต้องใส่นาฬิกาสองเรือนบนข้อมือเดียวกัน ซึ่งทั้งไม่สะดวกและน่าขัน เขาจึงเสนอว่า Apple ควรทำ Smart Ring ที่สามารถติดตามสุขภาพได้เหมือน Apple Watch แต่เล็กกะทัดรัดและไม่รบกวนการใส่นาฬิกาแบบดั้งเดิม หาก Apple ทำจริงก็อาจกลายเป็นผลิตภัณฑ์ที่พลิกเกมในปี 2026
https://www.techradar.com/health-fitness/smartwatches/apple-needs-to-make-a-smart-ring-to-save-me-from-this-ridiculous-situation รีวิวซอฟต์แวร์ Idea Spectrum Realtime Landscaping Pro 2025
นี่คือโปรแกรมออกแบบภูมิทัศน์ที่ให้คุณสร้างสวนเสมือนจริงได้จากคอมพิวเตอร์ Windows จุดเด่นคืออินเทอร์เฟซที่ใช้งานง่าย มีคลังพืชกว่า 6,000 ชนิด และวัตถุสามมิติหลากหลาย ตั้งแต่เฟอร์นิเจอร์ไปจนถึงรถยนต์ พร้อมระบบแอนิเมชันที่ทำให้งานออกแบบดูมีชีวิตชีวา โปรแกรมยังมี Wizard ที่ช่วยให้การสร้างบ้าน สระน้ำ หรือสวนทำได้รวดเร็ว แม้จะมีข้อจำกัดว่าใช้ได้เฉพาะ Windows และอาจหน่วงเมื่อโปรเจ็กต์ซับซ้อน แต่ก็ถือเป็นเครื่องมือที่ทรงพลังสำหรับทั้งมือสมัครเล่นและมืออาชีพ
https://www.techradar.com/pro/software-services/idea-spectrum-realtime-landscaping-pro-review 📌📡🩷 รวมข่าวจากเวบ TechRadar 🩷📡📌
#รวมข่าวIT #20251216 #TechRadar
🖥️ LG เปิดตัวทีวี Micro RGB evo ที่ CES 2026
LG กำลังสร้างความฮือฮาในงาน CES 2026 ด้วยการเปิดตัวทีวีรุ่นใหม่ที่ใช้เทคโนโลยี Micro RGB evo ซึ่งเปลี่ยนหลอดไฟ LED แบบเดิมไปเป็นหลอดไฟสีแดง เขียว และน้ำเงินขนาดจิ๋ว เพื่อควบคุมแสงและสีได้ละเอียดขึ้น ผลลัพธ์คือภาพที่สว่างสดใสและสีสันจัดเต็มใกล้เคียง OLED แต่ยังคงความสว่างสูงของ LCD จุดเด่นคือการครอบคลุมสีครบทั้ง BT.2020, DCI-P3 และ Adobe RGB พร้อมระบบประมวลผล α11 AI Gen 3 ที่ช่วยอัปสเกลภาพให้คมชัดขึ้น ถือเป็นการพยายามปิดช่องว่างระหว่าง LCD และ OLED ที่น่าสนใจมากสำหรับคนรักภาพคมชัดและสีสดใส
🔗 https://www.techradar.com/televisions/lg-reveals-micro-rgb-evo-tv-with-bold-claims-of-perfect-color
📺 Netflix เลิกใช้ Google Cast แต่ Apple TV บน Android นำกลับมาอีกครั้ง
Netflix เคยยกเลิกฟีเจอร์ Google Cast ที่ให้ผู้ใช้ส่งภาพจากมือถือขึ้นจอทีวี แต่ล่าสุด Apple TV บน Android กลับนำฟีเจอร์นี้กลับมา ทำให้ผู้ใช้สามารถสตรีมคอนเทนต์จากมือถือไปยังทีวีได้อีกครั้ง การเคลื่อนไหวนี้สะท้อนถึงการแข่งขันในตลาดสตรีมมิ่งที่ยังคงดุเดือด และการที่ Apple พยายามทำให้บริการของตนเข้าถึงผู้ใช้ Android ได้สะดวกขึ้น
🔗 https://www.techradar.com/streaming/apple-tv-plus/netflix-dropped-google-cast-now-apple-tv-for-android-just-brought-it-back
💾 NAS พกพาใส่ SSD 4 ตัว พร้อมพลัง Intel N150
มีการเปิดตัวอุปกรณ์ NAS ขนาดเล็กที่ดูเหมือนวิทยุทรานซิสเตอร์เก่า แต่ภายในบรรจุ SSD ได้ถึง 4 ตัว ใช้พลังจาก Intel N150 และมีพอร์ต LAN 2.5Gb สองช่อง รวมถึง RAM 12GB จุดขายคือความสามารถในการพกพาและเก็บข้อมูลได้มาก แต่ก็มีค่าใช้จ่ายแฝงที่อาจเกินความคาดหมาย เหมาะสำหรับคนที่ต้องการระบบจัดเก็บข้อมูลที่คล่องตัวและมีสไตล์ไม่เหมือนใคร
🔗 https://www.techradar.com/pro/is-that-your-grandads-transistor-radio-no-its-a-4-ssd-nas-with-two-2-5gb-lan-ports-12gb-ram-and-a-cracking-name-the-orange-colored-youyeetoo-nestdisk
🔐 นักพัฒนาสร้างกล่องสำรองข้อมูล iPhone แบบออฟไลน์
นักพัฒนารายหนึ่งได้สร้างอุปกรณ์สำรองข้อมูล iPhone ที่ไม่ต้องพึ่งพาคลาวด์ แต่ใช้การเชื่อมต่อผ่าน USB และเข้ารหัสข้อมูลเพื่อเก็บไว้ในเครื่องโดยตรง ถือเป็นทางเลือกใหม่สำหรับคนที่ไม่อยากจ่ายค่าบริการ iCloud หรือกังวลเรื่องความปลอดภัยของข้อมูลบนคลาวด์ แม้จะยังไม่เหมาะกับผู้ใช้ทั่วไป แต่แนวคิดนี้สะท้อนถึงความต้องการควบคุมข้อมูลส่วนตัวมากขึ้น
🔗 https://www.techradar.com/pro/want-to-back-up-your-iphone-securely-without-paying-the-apple-tax-theres-a-hack-for-that-but-it-isnt-for-everyone-yet
🎮 วิกฤติ RAM อาจกระทบหนักต่อโน้ตบุ๊กเกมมิ่ง
ตลาดโน้ตบุ๊กเกมมิ่งกำลังเผชิญปัญหาวิกฤติ RAM ที่อาจทำให้เครื่องเล่นเกมประสิทธิภาพสูงมีราคาสูงขึ้นและหายากขึ้น เหตุผลมาจากความต้องการหน่วยความจำที่เพิ่มขึ้นทั่วโลก ทั้งจาก AI และการประมวลผลข้อมูลขนาดใหญ่ ส่งผลให้ผู้ผลิตโน้ตบุ๊กเกมมิ่งต้องปรับตัวและอาจทำให้ผู้เล่นเกมต้องจ่ายแพงกว่าเดิมเพื่อได้เครื่องที่แรงพอ
🔗 https://www.techradar.com/computing/memory/the-ram-crisis-will-be-a-disaster-for-gaming-laptops-heres-why
🗑️ Slop: คำแห่งปีที่สะท้อนอินเทอร์เน็ตเต็มไปด้วยขยะดิจิทัล
ปีนี้ Merriam-Webster เลือกคำว่า “Slop” เป็น Word of the Year 2025 เพื่ออธิบายเนื้อหาดิจิทัลคุณภาพต่ำที่ถูกผลิตขึ้นอย่างมหาศาลด้วย AI ไม่ว่าจะเป็นบทความ ภาพ วิดีโอ หรือพอดแคสต์ หลายอย่างดูเหมือนจะสร้างได้ง่ายแต่กลับทำให้โลกออนไลน์เต็มไปด้วยสิ่งที่คนเรียกว่า “AI slop” จนยากจะแยกออกว่าอะไรคือผลงานมนุษย์จริงๆ และอะไรคือสิ่งที่เครื่องจักรสร้างขึ้นมา เรื่องนี้สะท้อนว่าพลังของเครื่องมือ AI ถูกส่งถึงมือผู้ใช้เร็วเกินไปโดยที่ยังไม่ทันคิดถึงผลกระทบ ทำให้เราต้องเผชิญกับทะเลข้อมูลที่ปะปนทั้งคุณภาพและขยะไปพร้อมกัน
🔗 https://www.techradar.com/ai-platforms-assistants/we-filled-the-internet-with-garbage-and-now-slop-is-the-word-of-the-year-nice-going-ai
💻 Super X: แท็บเล็ตลูกผสมที่แรงระดับเดสก์ท็อป
OneXPlayer เปิดตัว Super X อุปกรณ์ลูกผสมที่รวมแท็บเล็ตกับพลังการประมวลผลระดับเดสก์ท็อป หน้าจอใหญ่ถึง 14 นิ้ว มาพร้อมซีพียู 16 คอร์ GPU ระดับ 5060-class และ RAM สูงสุด 128GB จุดเด่นคือการออกแบบระบบระบายความร้อนด้วยน้ำ ทำให้เครื่องเล็กแต่ยังคงประสิทธิภาพสูง เหมาะกับคนที่อยากได้ความแรงแบบ PC แต่ยังพกพาได้สะดวก แม้ราคาคาดว่าจะไม่ต่ำกว่า 2000 ดอลลาร์ แต่ถือเป็นการยกระดับแท็บเล็ตให้ก้าวไปอีกขั้น
🔗 https://www.techradar.com/pro/a-water-cooled-amd-ai-14-inch-tablet-with-16-cpu-cores-a-5060-class-gpu-and-128gb-ram-is-exactly-what-i-need-for-christmas-i-dont-think-it-will-cost-less-than-usd2000-though
💾 SSD จิ๋วแต่แรง: Samsung เปิดตัว PCIe Gen5 รุ่นใหม่
Samsung เผยโฉม SSD รุ่น PM9E1 ที่มาในขนาดเล็กเพียง 22 x 42 มม. แต่รองรับมาตรฐาน PCIe Gen5 ทำให้ได้ความเร็วสูงและความจุที่จริงจัง แม้จะมาแบบเงียบๆ แต่ถือเป็นการขยายตลาดสู่กลุ่มผู้ใช้ที่ต้องการอุปกรณ์เก็บข้อมูลขนาดเล็กแต่ไม่ลดทอนประสิทธิภาพ เหมาะกับโน้ตบุ๊กหรืออุปกรณ์พกพาที่ต้องการความเร็วระดับสูงสุดในพื้นที่จำกัด
🔗 https://www.techradar.com/pro/samsungs-surprising-stealth-superfast-ssd-surfaces-silently-pm9e1-turns-out-to-be-a-mini-9100-pro-measuring-just-22-x-42mm-with-pcie-gen5-capabilities
🎮 DoomScroll: เว็บไซต์ใหม่รวมแผนที่ Doom แบบไม่รู้จบ
แฟนเกม Doom ได้เฮ เมื่อมีเว็บไซต์ใหม่ชื่อ DoomScroll ที่รวบรวมแผนที่เกม Doom ไว้ให้เลือกเล่นได้ไม่รู้จบผ่านเบราว์เซอร์ ผู้เล่นสามารถเข้าไปเลือกแผนที่ที่ชอบแล้วเล่นได้ทันที ถือเป็นการเปิดคลังเกมคลาสสิกให้เข้าถึงง่ายขึ้น และยังทำให้ชุมชนผู้เล่นสามารถแชร์ผลงานกันได้สะดวกขึ้นด้วย
🔗 https://www.techradar.com/gaming/pc-gaming/new-doomscroll-website-is-an-endless-library-of-doom-maps-you-can-pick-from-and-play-in-your-browser
🧠 หน่วยความจำแห่งอนาคต: Kioxia พัฒนา 3D DRAM
Kioxia ประกาศความสำเร็จในการพัฒนาเทคโนโลยี 3D DRAM โดยใช้ stacked oxide-semiconductors ซึ่งช่วยลดต้นทุนการผลิตและเพิ่มความหนาแน่นของหน่วยความจำ แม้จะยังไม่พร้อมสู่ตลาดผู้บริโภคในทันที แต่ถือเป็นก้าวสำคัญที่จะเปลี่ยนโฉมอุตสาหกรรมหน่วยความจำในทศวรรษหน้า ทำให้คาดหวังได้ว่าอนาคตเราจะได้เห็น RAM ที่เร็วขึ้นและราคาถูกลง
🔗 https://www.techradar.com/pro/crying-over-expensive-ram-kioxia-may-have-cracked-the-3d-ram-puzzle-paving-the-way-for-cheaper-faster-memory-but-it-probably-wont-reach-the-market-till-the-next-decade
🛡️ Apple อุดช่องโหว่ Zero-Day สุดอันตราย
Apple ออกแพตช์แก้ไขช่องโหว่ร้ายแรงใน WebKit ที่ถูกใช้โจมตีแบบเจาะจงบุคคลระดับสูง โดยช่องโหว่นี้อาจเปิดทางให้แฮกเกอร์เข้าควบคุมเครื่องจากระยะไกลได้ ทีม Google TAG และ Apple ร่วมกันค้นพบและแก้ไข ซึ่งถือเป็นการทำงานร่วมกันที่ไม่ค่อยเกิดขึ้นบ่อยนัก การอัปเดตครอบคลุมทั้ง iOS, iPadOS, macOS, watchOS, tvOS, visionOS และ Safari ผู้ใช้ทั่วไปแม้จะไม่ใช่เป้าหมายหลัก แต่ก็ถูกแนะนำให้รีบอัปเดตเพื่อความปลอดภัยทันที
🔗 https://www.techradar.com/pro/security/apple-says-it-fixed-zero-day-flaws-used-for-sophisticated-attacks
🌐 CEO Windscribe วิจารณ์การแบน VPN สำหรับเด็ก
Windscribe ผู้ให้บริการ VPN ออกมาแสดงความเห็นว่าการห้ามเด็กใช้ VPN เป็น “วิธีแก้ที่แย่ที่สุด” เพราะ VPN ไม่ใช่เครื่องมืออันตราย แต่กลับเป็นสิ่งที่ช่วยปกป้องความเป็นส่วนตัวและความปลอดภัย การแบนอาจทำให้เด็กขาดโอกาสในการเรียนรู้การใช้งานอินเทอร์เน็ตอย่างปลอดภัย และยังไม่แก้ปัญหาที่แท้จริงของการใช้งานออนไลน์
🔗 https://www.techradar.com/vpn/vpn-privacy-security/banning-vpns-for-kids-is-the-dumbest-possible-fix-windscribe-ceo
📷 กล้องวงจรปิดแบตเตอรี่ไร้ขีดจำกัด
มีการเปิดตัวกล้องวงจรปิดรุ่นใหม่ที่ชูจุดขายเรื่อง “แบตเตอรี่ไม่จำกัด” สามารถทำงานได้ตลอด 24 ชั่วโมงโดยไม่ต้องกังวลเรื่องการชาร์จบ่อย ๆ ราคาก็ไม่สูงอย่างที่คิด ทำให้ผู้ใช้ทั่วไปสามารถเข้าถึงได้ง่ายขึ้น กล้องนี้เหมาะสำหรับผู้ที่ต้องการความปลอดภัยต่อเนื่องโดยไม่ต้องยุ่งยากกับการบำรุงรักษาแบตเตอรี่
🔗 https://www.techradar.com/home/smart-home/this-home-security-cam-monitors-your-property-24-7-with-unlimited-battery-life-and-it-costs-less-than-you-might-expect
⌚ Garmin เผลอหลุดข้อมูล Vivosmart 6
Garmin มีข่าวหลุดเกี่ยวกับสมาร์ทแทร็กเกอร์รุ่นใหม่ Vivosmart 6 ที่คาดว่าจะมาพร้อมการอัปเกรดสำคัญเหนือรุ่นก่อน แม้ยังไม่มีรายละเอียดเต็ม แต่คาดว่าจะมีฟีเจอร์ด้านสุขภาพและการติดตามการออกกำลังกายที่แม่นยำขึ้น การหลุดครั้งนี้สร้างความตื่นเต้นให้กับผู้ที่ติดตามอุปกรณ์สวมใส่ของ Garmin อยู่แล้ว
🔗 https://www.techradar.com/health-fitness/fitness-trackers/garmin-just-leaked-its-vivosmart-6-tracker-and-it-might-come-with-one-major-upgrade-over-its-predecessor
🔒 แอป Freedom Chat ทำข้อมูลผู้ใช้หลุด
มีรายงานว่าแอปแชทชื่อ Freedom Chat เผยข้อมูลผู้ใช้โดยไม่ได้ตั้งใจ ทั้งหมายเลขโทรศัพท์และรายละเอียดอื่น ๆ ทำให้เกิดความกังวลเรื่องความปลอดภัยและความเป็นส่วนตัวของผู้ใช้ แอปนี้ถูกวิจารณ์อย่างหนักว่าขาดมาตรการป้องกันที่รัดกุม และอาจทำให้ผู้ใช้เสี่ยงต่อการถูกโจมตีหรือการละเมิดข้อมูล
🔗 https://www.techradar.com/pro/security/messaging-app-freedom-chat-exposes-user-phone-numbers-and-more-heres-what-we-know
🎧 Google เปิดฟีเจอร์แปลสดผ่านหูฟัง
Google กำลังยกระดับการสื่อสารข้ามภาษาให้ก้าวไปอีกขั้น ด้วยการเปิดตัวฟีเจอร์ “Live Translation” ที่สามารถใช้งานได้กับหูฟังทุกยี่ห้อ ไม่จำกัดเฉพาะ Pixel Buds อีกต่อไป โดยเริ่มทดสอบในสหรัฐฯ เม็กซิโก และอินเดีย ฟีเจอร์นี้ไม่เพียงแค่แปลคำต่อคำ แต่ยังรักษาน้ำเสียง จังหวะ และอารมณ์ของผู้พูด ทำให้การสนทนาเป็นธรรมชาติมากขึ้น นอกจากนี้ Google ยังปรับปรุงระบบ Gemini ให้เข้าใจสำนวนและภาษาพูด เช่น “stealing my thunder” ที่ไม่สามารถแปลตรงตัวได้ พร้อมทั้งเพิ่มเครื่องมือช่วยเรียนภาษา เช่น การให้คำแนะนำด้านการออกเสียง และระบบติดตามความก้าวหน้า ฟีเจอร์นี้รองรับกว่า 70 ภาษา และมีแผนจะขยายไปยัง iOS ในปี 2026
🔗 https://www.techradar.com/computing/software/google-smashes-language-barriers-with-live-translation-for-any-earbuds-on-android-heres-how-it-works
📧 อีเมลไม่ใช่จุดอ่อน แต่การตั้งค่าคลาวด์ต่างหาก
หลายครั้งที่เกิดเหตุข้อมูลรั่วไหล อีเมลมักถูกมองว่าเป็นตัวการ แต่จริง ๆ แล้วปัญหามาจากการตั้งค่าคลาวด์ที่ผิดพลาดมากกว่า กว่า 99% ของความล้มเหลวด้านความปลอดภัยเกิดจากผู้ใช้เอง เช่น คลิกลิงก์ฟิชชิ่ง ใช้รหัสผ่านซ้ำ หรือจัดการข้อมูลผิดพลาด การโทษอีเมลจึงเป็นการเบี่ยงเบนความสนใจไปจากต้นเหตุที่แท้จริง ผู้เชี่ยวชาญแนะนำว่าการป้องกันควรเริ่มจากการเข้ารหัสข้อมูล การเสริมความปลอดภัยของระบบปฏิบัติการ และการฝึกอบรมผู้ใช้ให้รู้เท่าทันภัยไซเบอร์ เมื่อผู้ใช้มีความรู้และระบบถูกเข้ารหัสอย่างดี อีเมลก็จะกลายเป็นพื้นที่ที่ปลอดภัยและมีประสิทธิภาพมากขึ้น
🔗 https://www.techradar.com/pro/your-email-app-isnt-the-weak-link-but-your-cloud-configuration-probably-is
🛡️ Microsoft ขยายโครงการ Bug Bounty
Microsoft ประกาศปรับโครงการ Bug Bounty ครั้งใหญ่ เปิดให้ผู้เชี่ยวชาญด้านความปลอดภัยสามารถส่งรายงานช่องโหว่ได้ครอบคลุมทุกผลิตภัณฑ์และบริการ แม้บางโปรแกรมจะไม่มีการตั้งค่ารางวัลอย่างเป็นทางการก็ตาม แนวทางใหม่นี้เรียกว่า “In Scope by Default” ซึ่งหมายความว่าหากช่องโหว่มีผลกระทบต่อบริการออนไลน์ของ Microsoft ก็จะได้รับเงินรางวัลตามระดับความรุนแรง โดยปีที่ผ่านมา Microsoft จ่ายเงินรางวัลไปกว่า 17 ล้านดอลลาร์ มากกว่า Google ที่จ่ายราว 11.8 ล้านดอลลาร์ การขยายนี้ครอบคลุมทั้งโค้ดของ Microsoft โค้ดจากบุคคลที่สาม และโอเพ่นซอร์ส ถือเป็นการสร้างแรงจูงใจให้ผู้เชี่ยวชาญช่วยตรวจสอบความปลอดภัยในวงกว้างยิ่งขึ้น
🔗 https://www.techradar.com/pro/security/microsoft-will-expand-bug-bounties-even-on-programs-without-official-payouts
🏢 Oracle ทุ่มมหาศาลกับดีลศูนย์ข้อมูล
Oracle กำลังเดินเกมครั้งใหญ่ในโลกคลาวด์และศูนย์ข้อมูล ล่าสุดมีการเปิดเผยว่าได้ทำสัญญาเช่าศูนย์ข้อมูลและคลาวด์รวมมูลค่าถึง 248 พันล้านดอลลาร์ ซึ่งจะทยอยเริ่มใช้ตั้งแต่ปี 2026 ไปจนถึง 2028 และกินเวลายาวนานถึง 15–19 ปี การขยายตัวนี้เกิดจากความต้องการที่เพิ่มขึ้นอย่างต่อเนื่อง ทั้งจากลูกค้าใหญ่ ๆ อย่าง Meta, Nvidia และ OpenAI ที่เพิ่งเซ็นสัญญาเพิ่มอีก 300 พันล้านดอลลาร์ ทำให้ Oracle ต้องเพิ่มกำลังการผลิตไฟฟ้าและลงทุนเพิ่มหนี้อีกหลายหมื่นล้าน แม้จะเป็นภาระ แต่ก็สะท้อนว่าบริษัทกำลังเดิมพันอนาคตไว้กับการเติบโตของตลาด AI และคลาวด์อย่างเต็มที่
🔗 https://www.techradar.com/pro/oracle-reportedly-signs-major-huge-cloud-data-center-deals-in-the-last-quarter-nearly-usd250-billion-in-new-commitments-revealed
🤖 ChatGPT 5.2 vs Gemini 3
มีการทดสอบเปรียบเทียบสองแชตบอทที่โด่งดังที่สุดในโลกตอนนี้ คือ ChatGPT 5.2 และ Gemini 3 ผู้เขียนลองใช้งานจริงเพื่อดูว่าใครตอบโจทย์ได้ดีกว่า ผลลัพธ์ออกมาน่าสนใจเพราะแต่ละตัวมีจุดแข็งต่างกัน ChatGPT 5.2 โดดเด่นเรื่องการให้คำตอบที่ละเอียดและมีความคิดเชิงลึก ส่วน Gemini 3 เน้นความเร็วและความกระชับในการสื่อสาร การแข่งขันนี้สะท้อนว่าตลาด AI กำลังร้อนแรง และผู้ใช้ก็มีทางเลือกมากขึ้นตามสไตล์ที่ต้องการ
🔗 https://www.techradar.com/ai-platforms-assistants/chatgpt/chatgpt-5-2-vs-gemini-3-i-tried-the-worlds-most-popular-chatbots-to-see-which-is-best-and-the-result-might-surprise-you
🎨 โลกเสมือนที่มีหัวใจมนุษย์
เรื่องราวของ Victoria Fard ศิลปินที่ใช้พลังของคอมพิวเตอร์ที่ขับเคลื่อนด้วย Snapdragon สร้างโลกเสมือนที่เต็มไปด้วยความรู้สึกและความเป็นมนุษย์ เธอไม่ได้มองเทคโนโลยีเป็นเพียงเครื่องมือ แต่ใช้มันเพื่อถ่ายทอดความทรงจำ ความรู้สึก และเรื่องราวที่เชื่อมโยงผู้คนเข้าด้วยกัน ผลงานของเธอจึงไม่ใช่แค่ภาพสวย ๆ แต่เป็นการสร้างพื้นที่ที่ผู้คนสามารถสัมผัสความเป็นมนุษย์ผ่านโลกดิจิทัลได้อย่างลึกซึ้ง
🔗 https://www.techradar.com/tech/memories-in-pixel-how-victoria-fard-uses-a-pc-powered-by-snapdragon-to-build-worlds-that-are-deeply-human
💼 ซีอีโอยังเดินหน้าลงทุน AI แม้ผลลัพธ์ไม่ชัด
แม้หลายบริษัทจะยังไม่เห็นผลลัพธ์ที่ชัดเจนจากการลงทุนใน AI แต่ซีอีโอจำนวนมากก็ยังคงเดินหน้าทุ่มงบต่อไป เหตุผลคือพวกเขามองว่า AI เป็นเทคโนโลยีที่ไม่สามารถมองข้ามได้ และหากหยุดลงทุนอาจเสียโอกาสในอนาคต ถึงแม้จะมีความเสี่ยงและความไม่แน่นอน แต่การตัดสินใจนี้สะท้อนถึงความเชื่อมั่นว่าการลงทุนใน AI จะเป็นกุญแจสำคัญในการแข่งขันระยะยาว
🔗 https://www.techradar.com/pro/ceos-seem-determined-to-keep-spending-on-ai-despite-mixed-success
⚖️ ศาลรัสเซียสั่งอายัดทรัพย์ Google ในฝรั่งเศส
มีข่าวใหญ่จากยุโรป เมื่อศาลรัสเซียมีคำสั่งให้อายัดทรัพย์สินของ Google ในฝรั่งเศสมูลค่ากว่า 129 ล้านดอลลาร์ สาเหตุเกี่ยวข้องกับข้อพิพาททางกฎหมายและการดำเนินธุรกิจที่ซับซ้อนในหลายประเทศ เหตุการณ์นี้สะท้อนถึงแรงกดดันที่บริษัทยักษ์ใหญ่ด้านเทคโนโลยีต้องเผชิญในระดับโลก ทั้งจากกฎระเบียบและความขัดแย้งทางการเมืองที่ส่งผลต่อการดำเนินงาน
🔗 https://www.techradar.com/pro/security/russian-court-ruling-could-see-usd129-million-freeze-on-some-of-googles-french-assets
📰 Microsoft เจอศึกใหญ่เรื่อง Cloud Licensing ในสหราชอาณาจักร
เรื่องนี้เริ่มจากการที่ Microsoft ถูกกล่าวหาว่ากำหนดเงื่อนไขการใช้งาน Windows Server บน Cloud ของคู่แข่งอย่าง AWS และ Google Cloud ให้ยุ่งยากและมีค่าใช้จ่ายสูง จนทำให้หลายองค์กรในสหราชอาณาจักรเสียเงินไปเป็นจำนวนมาก คดีนี้ถูกยื่นต่อศาล Competition Appeal Tribunal โดยมีองค์กรกว่า 59,000 แห่งเข้าร่วมเป็นกลุ่มฟ้องร้อง หาก Microsoft ถูกตัดสินว่าผิดจริง อาจต้องจ่ายค่าชดเชยสูงถึง 2 พันล้านปอนด์ ขณะที่ Microsoft ยืนยันว่าเป็นเพียงการกล่าวหาเกินจริงจากกลุ่มทนายและผู้สนับสนุน แต่แรงกดดันก็ยังคงมีต่อเนื่อง เพราะ Google เองก็เคยร้องเรียนเรื่องนี้ต่อ EU มาก่อนแล้ว
🔗 https://www.techradar.com/pro/microsoft-is-back-in-court-in-the-uk-over-unfair-cloud-licensing-claims
🎮 UGreen เปิดตัว eGPU Dock ท้าชน Razer ในตลาด eGPU ที่กำลังร้อนแรง
UGreen ได้เปิดตัว Linkstation eGPU Dock ที่มาพร้อมพลังงานในตัวถึง 850W และพอร์ตเชื่อมต่อใหม่อย่าง Oculink และ USB4 จุดเด่นคือราคาประมาณ 325 ดอลลาร์ ซึ่งใกล้เคียงกับ Razer Core X V2 แต่เหนือกว่าตรงที่มี PSU ในตัวและรองรับการ์ดจอขนาดใหญ่ถึง 370 มม. อย่างไรก็ตาม ดีไซน์ของ UGreen ยังเปิดโล่งมากกว่า Razer ที่มีโครงสร้างปิด ทำให้บางคนกังวลเรื่องความปลอดภัยของการ์ดจอ ถึงอย่างนั้น นี่ก็ถือเป็นการก้าวเข้าสู่ตลาดใหม่ที่น่าจับตามองของ UGreen ที่เดิมทำอุปกรณ์เสริมอย่าง Dock และ Charger
🔗 https://www.techradar.com/computing/gpu/its-a-great-time-to-buy-an-egpu-and-ugreens-new-razer-rival-has-two-major-tricks-up-its-sleeve
📱 วิกฤติ RAM อาจทำให้สมาร์ทโฟนถอยหลังในปี 2026
นักวิเคราะห์เตือนว่าความต้องการ RAM ที่สูงขึ้นจากศูนย์ข้อมูล AI กำลังทำให้ราคาพุ่งขึ้น ส่งผลให้ผู้ผลิตสมาร์ทโฟนอาจต้องลดสเปกลง แทนที่จะเพิ่ม RAM เป็น 16GB ในรุ่นเรือธงใหม่ อาจยังคงอยู่ที่ 12GB หรือบางรุ่นอาจลดลงเหลือ 8GB สำหรับรุ่นกลาง และ 4GB สำหรับรุ่นล่าง ทั้งนี้แม้จะเป็นการคาดการณ์ แต่ก็มีความเป็นไปได้สูง เพราะตลาด AI กำลังดูดซับทรัพยากรไปอย่างมหาศาล ซึ่งอาจย้อนแย้งกับการพัฒนา AI บนมือถือที่ต้องใช้ RAM มากเช่นกัน
🔗 https://www.techradar.com/phones/the-ram-crisis-will-see-smartphone-specs-go-backwards-in-2026-experts-warn-heres-why
💍 Apple ควรทำ Smart Ring เพื่อแก้ปัญหาความยุ่งยากของ Smartwatch
ผู้เขียนเล่าประสบการณ์ตรงว่าแม้ Apple Watch จะมีฟีเจอร์ด้านสุขภาพและการออกกำลังกายที่ยอดเยี่ยม แต่ก็สร้างความลำบากใจเพราะเขาเป็นคนรักนาฬิกากลไกและไม่อยากละทิ้งการใส่นาฬิกาแบบดั้งเดิม จนต้องใส่นาฬิกาสองเรือนบนข้อมือเดียวกัน ซึ่งทั้งไม่สะดวกและน่าขัน เขาจึงเสนอว่า Apple ควรทำ Smart Ring ที่สามารถติดตามสุขภาพได้เหมือน Apple Watch แต่เล็กกะทัดรัดและไม่รบกวนการใส่นาฬิกาแบบดั้งเดิม หาก Apple ทำจริงก็อาจกลายเป็นผลิตภัณฑ์ที่พลิกเกมในปี 2026
🔗 https://www.techradar.com/health-fitness/smartwatches/apple-needs-to-make-a-smart-ring-to-save-me-from-this-ridiculous-situation
🌳 รีวิวซอฟต์แวร์ Idea Spectrum Realtime Landscaping Pro 2025
นี่คือโปรแกรมออกแบบภูมิทัศน์ที่ให้คุณสร้างสวนเสมือนจริงได้จากคอมพิวเตอร์ Windows จุดเด่นคืออินเทอร์เฟซที่ใช้งานง่าย มีคลังพืชกว่า 6,000 ชนิด และวัตถุสามมิติหลากหลาย ตั้งแต่เฟอร์นิเจอร์ไปจนถึงรถยนต์ พร้อมระบบแอนิเมชันที่ทำให้งานออกแบบดูมีชีวิตชีวา โปรแกรมยังมี Wizard ที่ช่วยให้การสร้างบ้าน สระน้ำ หรือสวนทำได้รวดเร็ว แม้จะมีข้อจำกัดว่าใช้ได้เฉพาะ Windows และอาจหน่วงเมื่อโปรเจ็กต์ซับซ้อน แต่ก็ถือเป็นเครื่องมือที่ทรงพลังสำหรับทั้งมือสมัครเล่นและมืออาชีพ
🔗 https://www.techradar.com/pro/software-services/idea-spectrum-realtime-landscaping-pro-review