

ปัญญาประดิษฐ์สายวิจัยที่ไม่หยุดแค่ “แชตบอต”
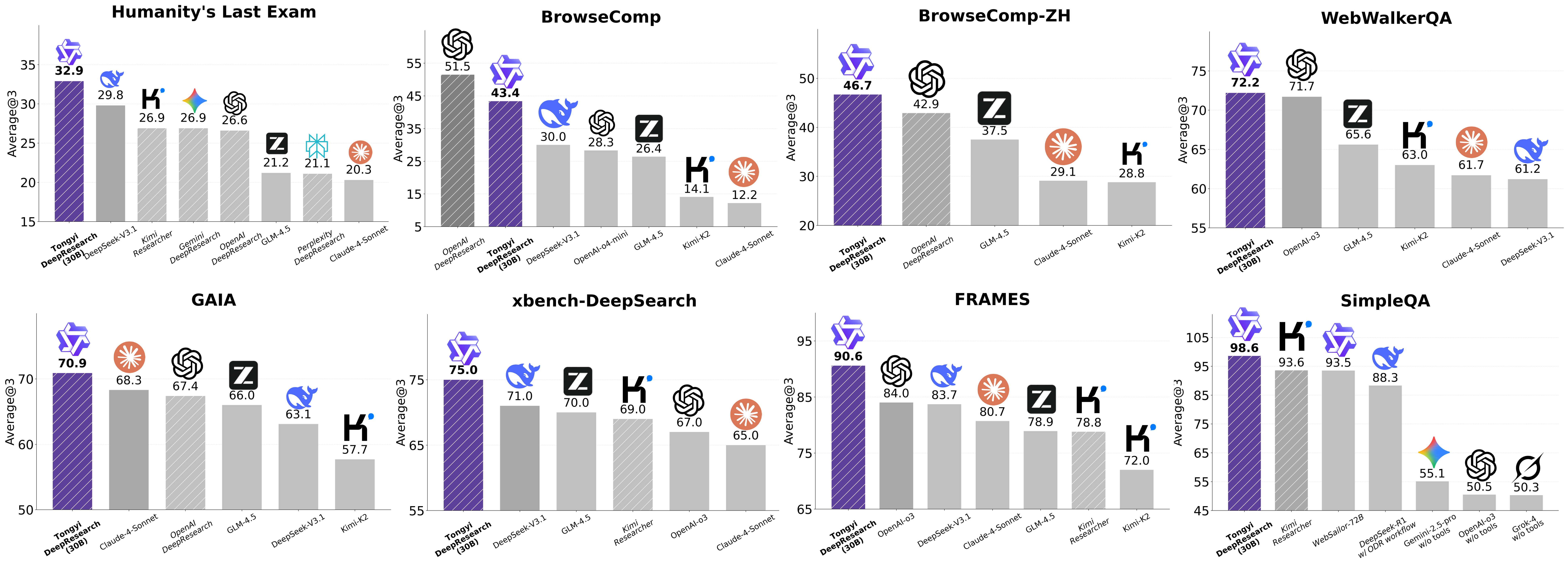
Tongyi DeepResearch เป็นโมเดล Web Agent แบบโอเพ่นซอร์สตัวแรกที่สามารถทำงานวิจัยเชิงลึกได้เทียบเท่ากับโมเดลเชิงพาณิชย์ของ OpenAI โดยมีคะแนนสูงในหลาย benchmark เช่น:
Humanity’s Last Exam (HLE): 32.9
BrowseComp: 43.4
BrowseComp-ZH: 46.7
xbench-DeepSearch: 75
โมเดลนี้ไม่ใช่แค่เก่งด้านการตอบคำถาม แต่ยังสามารถวางแผน ทำวิจัยหลายขั้นตอน และใช้เครื่องมือภายนอกได้อย่างมีประสิทธิภาพ โดยใช้ framework reasoning แบบ ReAct และโหมดขั้นสูงที่เรียกว่า Heavy Mode เพื่อจัดการงานที่ซับซ้อน
Tongyi DeepResearch เป็น Web Agent แบบโอเพ่นซอร์สที่ทรงพลัง
ทำงานได้เทียบเท่ากับ DeepResearch ของ OpenAI
ได้คะแนนสูงในหลาย benchmark ด้าน reasoning และการค้นคว้า
ใช้ข้อมูลสังเคราะห์คุณภาพสูงในการฝึก
สร้าง QA pairs จากกราฟความรู้และคลิกสตรีม
ใช้เทคนิคเพิ่มความยากของคำถามอย่างเป็นระบบ
มีระบบฝึกแบบครบวงจร: CPT → SFT → RL
Continual Pre-training ด้วยข้อมูลสังเคราะห์
Fine-tuning ด้วยข้อมูลผู้เชี่ยวชาญ
Reinforcement Learning แบบ on-policy เพื่อปรับพฤติกรรมให้ตรงเป้าหมาย
ใช้โครงสร้าง reasoning แบบ ReAct และ IterResearch
ReAct: วงจร Thought → Action → Observation
IterResearch: แบ่งงานวิจัยเป็นรอบ ๆ เพื่อรักษาโฟกัสและคุณภาพ reasoning
มีการใช้งานจริงในระบบของ Alibaba
เช่น “Xiao Gao” ผู้ช่วยด้านแผนที่ และ “FaRui” ผู้ช่วยด้านกฎหมาย
ทำงานวิจัยหลายขั้นตอนและให้ผลลัพธ์ที่ตรวจสอบได้
https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
Tongyi DeepResearch เป็นโมเดล Web Agent แบบโอเพ่นซอร์สตัวแรกที่สามารถทำงานวิจัยเชิงลึกได้เทียบเท่ากับโมเดลเชิงพาณิชย์ของ OpenAI โดยมีคะแนนสูงในหลาย benchmark เช่น:
Humanity’s Last Exam (HLE): 32.9
BrowseComp: 43.4
BrowseComp-ZH: 46.7
xbench-DeepSearch: 75
โมเดลนี้ไม่ใช่แค่เก่งด้านการตอบคำถาม แต่ยังสามารถวางแผน ทำวิจัยหลายขั้นตอน และใช้เครื่องมือภายนอกได้อย่างมีประสิทธิภาพ โดยใช้ framework reasoning แบบ ReAct และโหมดขั้นสูงที่เรียกว่า Heavy Mode เพื่อจัดการงานที่ซับซ้อน
Tongyi DeepResearch เป็น Web Agent แบบโอเพ่นซอร์สที่ทรงพลัง
ทำงานได้เทียบเท่ากับ DeepResearch ของ OpenAI
ได้คะแนนสูงในหลาย benchmark ด้าน reasoning และการค้นคว้า
ใช้ข้อมูลสังเคราะห์คุณภาพสูงในการฝึก
สร้าง QA pairs จากกราฟความรู้และคลิกสตรีม
ใช้เทคนิคเพิ่มความยากของคำถามอย่างเป็นระบบ
มีระบบฝึกแบบครบวงจร: CPT → SFT → RL
Continual Pre-training ด้วยข้อมูลสังเคราะห์
Fine-tuning ด้วยข้อมูลผู้เชี่ยวชาญ
Reinforcement Learning แบบ on-policy เพื่อปรับพฤติกรรมให้ตรงเป้าหมาย
ใช้โครงสร้าง reasoning แบบ ReAct และ IterResearch
ReAct: วงจร Thought → Action → Observation
IterResearch: แบ่งงานวิจัยเป็นรอบ ๆ เพื่อรักษาโฟกัสและคุณภาพ reasoning
มีการใช้งานจริงในระบบของ Alibaba
เช่น “Xiao Gao” ผู้ช่วยด้านแผนที่ และ “FaRui” ผู้ช่วยด้านกฎหมาย
ทำงานวิจัยหลายขั้นตอนและให้ผลลัพธ์ที่ตรวจสอบได้
https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
🧠 ปัญญาประดิษฐ์สายวิจัยที่ไม่หยุดแค่ “แชตบอต”
Tongyi DeepResearch เป็นโมเดล Web Agent แบบโอเพ่นซอร์สตัวแรกที่สามารถทำงานวิจัยเชิงลึกได้เทียบเท่ากับโมเดลเชิงพาณิชย์ของ OpenAI โดยมีคะแนนสูงในหลาย benchmark เช่น:
🔖 Humanity’s Last Exam (HLE): 32.9
🔖 BrowseComp: 43.4
🔖 BrowseComp-ZH: 46.7
🔖 xbench-DeepSearch: 75
โมเดลนี้ไม่ใช่แค่เก่งด้านการตอบคำถาม แต่ยังสามารถวางแผน ทำวิจัยหลายขั้นตอน และใช้เครื่องมือภายนอกได้อย่างมีประสิทธิภาพ โดยใช้ framework reasoning แบบ ReAct และโหมดขั้นสูงที่เรียกว่า Heavy Mode เพื่อจัดการงานที่ซับซ้อน
✅ Tongyi DeepResearch เป็น Web Agent แบบโอเพ่นซอร์สที่ทรงพลัง
➡️ ทำงานได้เทียบเท่ากับ DeepResearch ของ OpenAI
➡️ ได้คะแนนสูงในหลาย benchmark ด้าน reasoning และการค้นคว้า
✅ ใช้ข้อมูลสังเคราะห์คุณภาพสูงในการฝึก
➡️ สร้าง QA pairs จากกราฟความรู้และคลิกสตรีม
➡️ ใช้เทคนิคเพิ่มความยากของคำถามอย่างเป็นระบบ
✅ มีระบบฝึกแบบครบวงจร: CPT → SFT → RL
➡️ Continual Pre-training ด้วยข้อมูลสังเคราะห์
➡️ Fine-tuning ด้วยข้อมูลผู้เชี่ยวชาญ
➡️ Reinforcement Learning แบบ on-policy เพื่อปรับพฤติกรรมให้ตรงเป้าหมาย
✅ ใช้โครงสร้าง reasoning แบบ ReAct และ IterResearch
➡️ ReAct: วงจร Thought → Action → Observation
➡️ IterResearch: แบ่งงานวิจัยเป็นรอบ ๆ เพื่อรักษาโฟกัสและคุณภาพ reasoning
✅ มีการใช้งานจริงในระบบของ Alibaba
➡️ เช่น “Xiao Gao” ผู้ช่วยด้านแผนที่ และ “FaRui” ผู้ช่วยด้านกฎหมาย
➡️ ทำงานวิจัยหลายขั้นตอนและให้ผลลัพธ์ที่ตรวจสอบได้
https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
0 ความคิดเห็น
0 การแบ่งปัน
311 มุมมอง
0 รีวิว