

เรื่องเล่าใหม่: GPU ไม่ใช่แค่การ์ดจอ – แต่คือเครื่องจักรแห่งการเรียนรู้ของ AI
ในยุคที่ AI ใหญ่ขึ้นทุกวัน การเข้าใจว่า GPU ทำงานอย่างไรจึงสำคัญมาก โดยเฉพาะเมื่อเปรียบเทียบกับ TPU ที่ Google ใช้กันอย่างแพร่หลาย
GPU สมัยใหม่ เช่น NVIDIA H100, B200 และ GB200 NVL72 ไม่ได้เป็นแค่การ์ดจอสำหรับเล่นเกมอีกต่อไป แต่กลายเป็นเครื่องมือหลักในการฝึกและรันโมเดลขนาดใหญ่ (LLMs) ด้วยพลังการคำนวณมหาศาลจาก Tensor Core ที่ออกแบบมาเพื่อการคูณเมทริกซ์โดยเฉพาะ
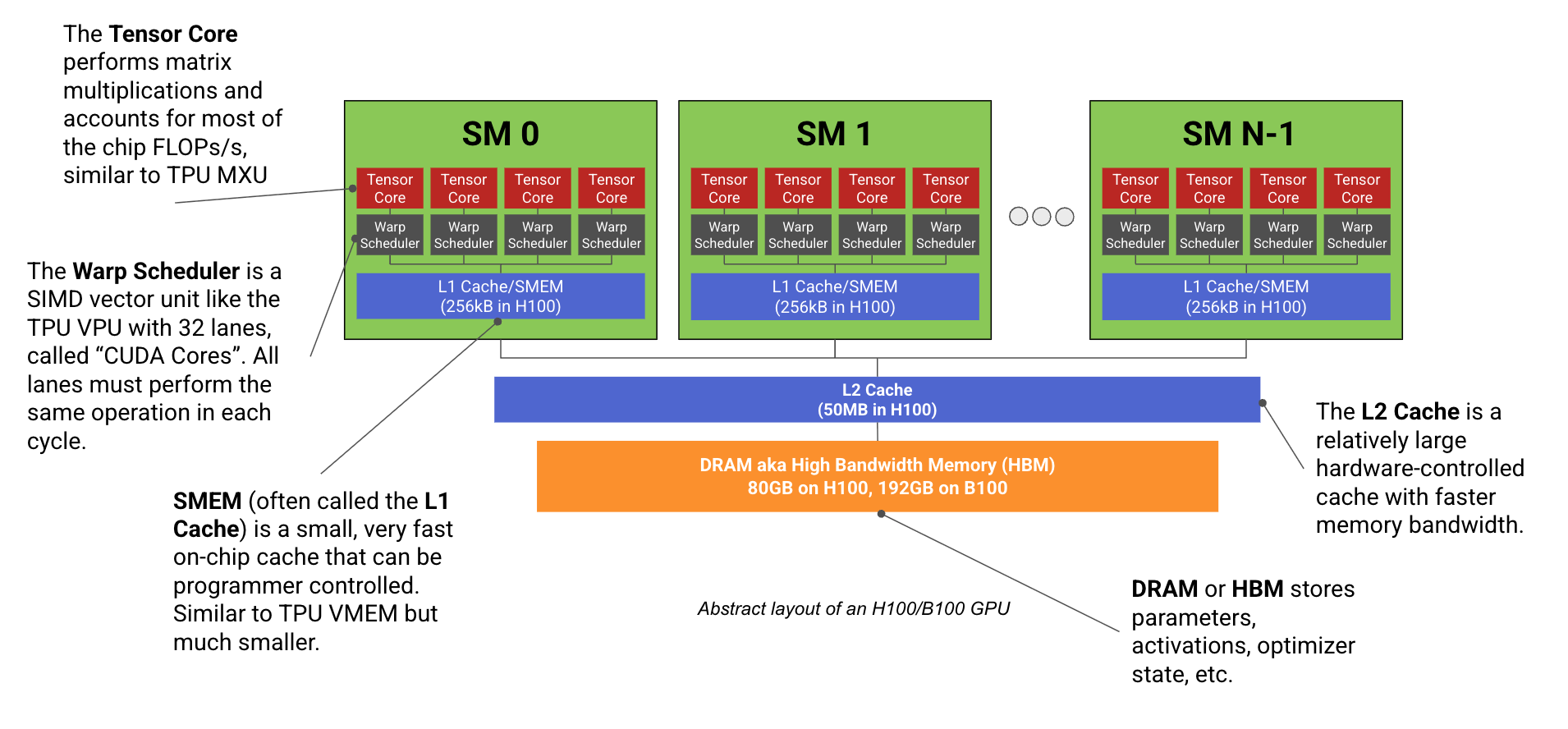
แต่ละ GPU ประกอบด้วยหลาย SM (Streaming Multiprocessor) ซึ่งใน H100 มีถึง 132 SM และใน B200 มี 148 SM โดยแต่ละ SM มี Tensor Core, Warp Scheduler และ CUDA Cores ที่ทำงานแบบ SIMD/SIMT เพื่อประมวลผลแบบขนาน
GPU ยังมีระบบหน่วยความจำหลายระดับ ตั้งแต่ Register, SMEM (L1 cache), L2 cache ไปจนถึง HBM (High Bandwidth Memory) ซึ่งใน B200 มีถึง 192GB และแบนด์วิดท์สูงถึง 9TB/s
นอกจากนี้ยังมีระบบเครือข่ายภายในและระหว่าง GPU ที่ซับซ้อน เช่น NVLink, NVSwitch และ InfiniBand ที่ช่วยให้ GPU หลายตัวทำงานร่วมกันได้อย่างมีประสิทธิภาพ โดยเฉพาะในระบบ DGX SuperPod ที่สามารถเชื่อมต่อ GPU ได้ถึง 1024 ตัว
GPU ยังรองรับการทำงานแบบ parallelism หลายรูปแบบ เช่น data parallelism, tensor parallelism, expert parallelism และ pipeline parallelism ซึ่งแต่ละแบบมีข้อดีข้อเสียต่างกัน และต้องเลือกใช้ให้เหมาะกับขนาดและโครงสร้างของโมเดล
ข้อมูลในข่าว
GPU สมัยใหม่เช่น H100 และ B200 มี Tensor Core สำหรับคูณเมทริกซ์โดยเฉพาะ
H100 มี 132 SM ส่วน B200 มี 148 SM แต่ละ SM มี Tensor Core, Warp Scheduler และ CUDA Cores
หน่วยความจำของ GPU มีหลายระดับ: Register, SMEM, L2 cache และ HBM
B200 มี HBM ขนาด 192GB และแบนด์วิดท์ 9TB/s
ระบบเครือข่ายภายในใช้ NVLink และ NVSwitch เชื่อม GPU ภายใน node
ระบบเครือข่ายระหว่าง node ใช้ InfiniBand แบบ fat tree topology
DGX SuperPod สามารถเชื่อม GPU ได้ถึง 1024 ตัว
GPU รองรับ parallelism หลายแบบ: data, tensor, expert และ pipeline
NVIDIA SHARP ช่วยให้การทำ AllReduce มีประสิทธิภาพมากขึ้น
GB200 NVL72 มี node ขนาดใหญ่ขึ้น (72 GPU) และแบนด์วิดท์สูงถึง 3.6TB/s
ข้อมูลเสริมจากภายนอก
RTX PRO 4000 Blackwell SFF เปิดตัวเมื่อ 11 ส.ค. 2025 มี Tensor Core รุ่นที่ 5
ใช้สถาปัตยกรรม Blackwell 2.0 บนกระบวนการผลิต 5nm โดย TSMC
มี 8960 CUDA cores และ 280 Tensor cores พร้อม GDDR7 ขนาด 24GB
ประสิทธิภาพ AI สูงขึ้น 2.5 เท่าเมื่อเทียบกับรุ่นก่อน
ใช้พลังงานเพียง 70W เหมาะกับเวิร์กสเตชันขนาดเล็ก
รองรับ PCIe 5.0 x8 และ DisplayPort 2.1b
https://jax-ml.github.io/scaling-book/gpus/
ในยุคที่ AI ใหญ่ขึ้นทุกวัน การเข้าใจว่า GPU ทำงานอย่างไรจึงสำคัญมาก โดยเฉพาะเมื่อเปรียบเทียบกับ TPU ที่ Google ใช้กันอย่างแพร่หลาย
GPU สมัยใหม่ เช่น NVIDIA H100, B200 และ GB200 NVL72 ไม่ได้เป็นแค่การ์ดจอสำหรับเล่นเกมอีกต่อไป แต่กลายเป็นเครื่องมือหลักในการฝึกและรันโมเดลขนาดใหญ่ (LLMs) ด้วยพลังการคำนวณมหาศาลจาก Tensor Core ที่ออกแบบมาเพื่อการคูณเมทริกซ์โดยเฉพาะ
แต่ละ GPU ประกอบด้วยหลาย SM (Streaming Multiprocessor) ซึ่งใน H100 มีถึง 132 SM และใน B200 มี 148 SM โดยแต่ละ SM มี Tensor Core, Warp Scheduler และ CUDA Cores ที่ทำงานแบบ SIMD/SIMT เพื่อประมวลผลแบบขนาน
GPU ยังมีระบบหน่วยความจำหลายระดับ ตั้งแต่ Register, SMEM (L1 cache), L2 cache ไปจนถึง HBM (High Bandwidth Memory) ซึ่งใน B200 มีถึง 192GB และแบนด์วิดท์สูงถึง 9TB/s
นอกจากนี้ยังมีระบบเครือข่ายภายในและระหว่าง GPU ที่ซับซ้อน เช่น NVLink, NVSwitch และ InfiniBand ที่ช่วยให้ GPU หลายตัวทำงานร่วมกันได้อย่างมีประสิทธิภาพ โดยเฉพาะในระบบ DGX SuperPod ที่สามารถเชื่อมต่อ GPU ได้ถึง 1024 ตัว
GPU ยังรองรับการทำงานแบบ parallelism หลายรูปแบบ เช่น data parallelism, tensor parallelism, expert parallelism และ pipeline parallelism ซึ่งแต่ละแบบมีข้อดีข้อเสียต่างกัน และต้องเลือกใช้ให้เหมาะกับขนาดและโครงสร้างของโมเดล
ข้อมูลในข่าว
GPU สมัยใหม่เช่น H100 และ B200 มี Tensor Core สำหรับคูณเมทริกซ์โดยเฉพาะ
H100 มี 132 SM ส่วน B200 มี 148 SM แต่ละ SM มี Tensor Core, Warp Scheduler และ CUDA Cores
หน่วยความจำของ GPU มีหลายระดับ: Register, SMEM, L2 cache และ HBM
B200 มี HBM ขนาด 192GB และแบนด์วิดท์ 9TB/s
ระบบเครือข่ายภายในใช้ NVLink และ NVSwitch เชื่อม GPU ภายใน node
ระบบเครือข่ายระหว่าง node ใช้ InfiniBand แบบ fat tree topology
DGX SuperPod สามารถเชื่อม GPU ได้ถึง 1024 ตัว
GPU รองรับ parallelism หลายแบบ: data, tensor, expert และ pipeline
NVIDIA SHARP ช่วยให้การทำ AllReduce มีประสิทธิภาพมากขึ้น
GB200 NVL72 มี node ขนาดใหญ่ขึ้น (72 GPU) และแบนด์วิดท์สูงถึง 3.6TB/s
ข้อมูลเสริมจากภายนอก
RTX PRO 4000 Blackwell SFF เปิดตัวเมื่อ 11 ส.ค. 2025 มี Tensor Core รุ่นที่ 5
ใช้สถาปัตยกรรม Blackwell 2.0 บนกระบวนการผลิต 5nm โดย TSMC
มี 8960 CUDA cores และ 280 Tensor cores พร้อม GDDR7 ขนาด 24GB
ประสิทธิภาพ AI สูงขึ้น 2.5 เท่าเมื่อเทียบกับรุ่นก่อน
ใช้พลังงานเพียง 70W เหมาะกับเวิร์กสเตชันขนาดเล็ก
รองรับ PCIe 5.0 x8 และ DisplayPort 2.1b
https://jax-ml.github.io/scaling-book/gpus/
🧠 เรื่องเล่าใหม่: GPU ไม่ใช่แค่การ์ดจอ – แต่คือเครื่องจักรแห่งการเรียนรู้ของ AI
ในยุคที่ AI ใหญ่ขึ้นทุกวัน การเข้าใจว่า GPU ทำงานอย่างไรจึงสำคัญมาก โดยเฉพาะเมื่อเปรียบเทียบกับ TPU ที่ Google ใช้กันอย่างแพร่หลาย
GPU สมัยใหม่ เช่น NVIDIA H100, B200 และ GB200 NVL72 ไม่ได้เป็นแค่การ์ดจอสำหรับเล่นเกมอีกต่อไป แต่กลายเป็นเครื่องมือหลักในการฝึกและรันโมเดลขนาดใหญ่ (LLMs) ด้วยพลังการคำนวณมหาศาลจาก Tensor Core ที่ออกแบบมาเพื่อการคูณเมทริกซ์โดยเฉพาะ
แต่ละ GPU ประกอบด้วยหลาย SM (Streaming Multiprocessor) ซึ่งใน H100 มีถึง 132 SM และใน B200 มี 148 SM โดยแต่ละ SM มี Tensor Core, Warp Scheduler และ CUDA Cores ที่ทำงานแบบ SIMD/SIMT เพื่อประมวลผลแบบขนาน
GPU ยังมีระบบหน่วยความจำหลายระดับ ตั้งแต่ Register, SMEM (L1 cache), L2 cache ไปจนถึง HBM (High Bandwidth Memory) ซึ่งใน B200 มีถึง 192GB และแบนด์วิดท์สูงถึง 9TB/s
นอกจากนี้ยังมีระบบเครือข่ายภายในและระหว่าง GPU ที่ซับซ้อน เช่น NVLink, NVSwitch และ InfiniBand ที่ช่วยให้ GPU หลายตัวทำงานร่วมกันได้อย่างมีประสิทธิภาพ โดยเฉพาะในระบบ DGX SuperPod ที่สามารถเชื่อมต่อ GPU ได้ถึง 1024 ตัว
GPU ยังรองรับการทำงานแบบ parallelism หลายรูปแบบ เช่น data parallelism, tensor parallelism, expert parallelism และ pipeline parallelism ซึ่งแต่ละแบบมีข้อดีข้อเสียต่างกัน และต้องเลือกใช้ให้เหมาะกับขนาดและโครงสร้างของโมเดล
✅ ข้อมูลในข่าว
➡️ GPU สมัยใหม่เช่น H100 และ B200 มี Tensor Core สำหรับคูณเมทริกซ์โดยเฉพาะ
➡️ H100 มี 132 SM ส่วน B200 มี 148 SM แต่ละ SM มี Tensor Core, Warp Scheduler และ CUDA Cores
➡️ หน่วยความจำของ GPU มีหลายระดับ: Register, SMEM, L2 cache และ HBM
➡️ B200 มี HBM ขนาด 192GB และแบนด์วิดท์ 9TB/s
➡️ ระบบเครือข่ายภายในใช้ NVLink และ NVSwitch เชื่อม GPU ภายใน node
➡️ ระบบเครือข่ายระหว่าง node ใช้ InfiniBand แบบ fat tree topology
➡️ DGX SuperPod สามารถเชื่อม GPU ได้ถึง 1024 ตัว
➡️ GPU รองรับ parallelism หลายแบบ: data, tensor, expert และ pipeline
➡️ NVIDIA SHARP ช่วยให้การทำ AllReduce มีประสิทธิภาพมากขึ้น
➡️ GB200 NVL72 มี node ขนาดใหญ่ขึ้น (72 GPU) และแบนด์วิดท์สูงถึง 3.6TB/s
✅ ข้อมูลเสริมจากภายนอก
➡️ RTX PRO 4000 Blackwell SFF เปิดตัวเมื่อ 11 ส.ค. 2025 มี Tensor Core รุ่นที่ 5
➡️ ใช้สถาปัตยกรรม Blackwell 2.0 บนกระบวนการผลิต 5nm โดย TSMC
➡️ มี 8960 CUDA cores และ 280 Tensor cores พร้อม GDDR7 ขนาด 24GB
➡️ ประสิทธิภาพ AI สูงขึ้น 2.5 เท่าเมื่อเทียบกับรุ่นก่อน
➡️ ใช้พลังงานเพียง 70W เหมาะกับเวิร์กสเตชันขนาดเล็ก
➡️ รองรับ PCIe 5.0 x8 และ DisplayPort 2.1b
https://jax-ml.github.io/scaling-book/gpus/
0 ความคิดเห็น
0 การแบ่งปัน
285 มุมมอง
0 รีวิว