

เรื่องเล่าจากโลก AI: “ราคาคำตอบ” ที่คุณอาจไม่เคยคิด
ลองจินตนาการว่า AI ที่คุณใช้ตอบคำถามหรือเขียนบทความนั้น คิดค่าบริการเป็น “จำนวนคำ” ที่มันอ่านและเขียนออกมา—หรือที่เรียกว่า “token” ซึ่งแต่ละ token คือเศษคำประมาณ 3–4 ตัวอักษร
ในปี 2025 นี้ ตลาด LLM API แข่งขันกันดุเดือด ผู้ให้บริการอย่าง OpenAI, Google, Anthropic และ xAI ต่างออกโมเดลใหม่พร้อมราคาที่หลากหลาย ตั้งแต่ราคาถูกสุดเพียง $0.07 ต่อ 1 ล้าน token ไปจนถึง $600 ต่อ 1 ล้าน token สำหรับโมเดลระดับสูงสุด!
สิ่งที่น่าสนใจคือ “ราคาสำหรับการตอบ” (output token) มักแพงกว่าการถาม (input token) ถึง 3–5 เท่า ทำให้การออกแบบ prompt ที่กระชับและฉลาดกลายเป็นกลยุทธ์สำคัญในการลดต้นทุน
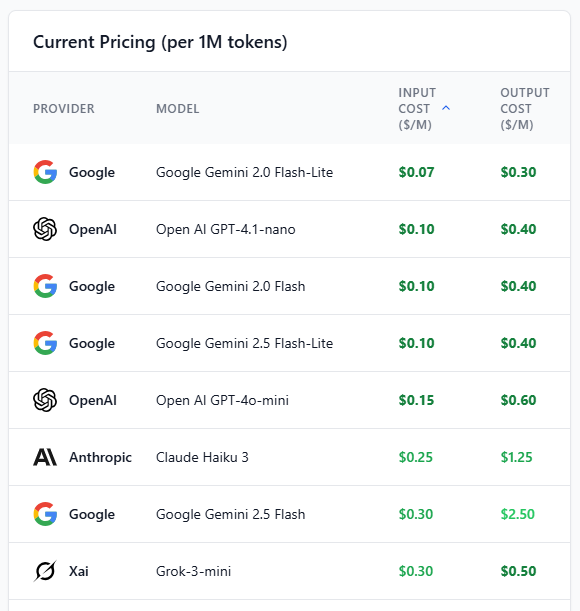
โมเดลราคาถูกที่สุดในตลาดตอนนี้ ได้แก่ Google Gemini 2.0 Flash-Lite และ OpenAI GPT-4.1-nano
ราคา input token อยู่ที่ $0.07–$0.10 ต่อ 1 ล้าน token
ราคา output token อยู่ที่ $0.30–$0.40 ต่อ 1 ล้าน token
โมเดลระดับกลางที่คุ้มค่า เช่น GPT-4o-mini และ Claude Haiku 3
ราคา input token อยู่ที่ $0.15–$0.25
ราคา output token อยู่ที่ $0.60–$1.25
โมเดลระดับสูง เช่น Claude Opus 4 และ GPT-o1-pro มีราคาสูงมาก
Claude Opus 4: $15 (input) / $75 (output)
GPT-o1-pro: $150 (input) / $600 (output)
แนวโน้มการตั้งราคาคือการแยก input กับ output token อย่างชัดเจน
output token แพงกว่า input token หลายเท่า
ส่งเสริมการใช้เทคนิค RAG (Retrieval-Augmented Generation) เพื่อประหยัด
ข้อมูลอัปเดตล่าสุดเมื่อวันที่ 27 กรกฎาคม 2025
แหล่งข้อมูลมาจากเว็บไซต์ทางการของผู้ให้บริการแต่ละราย
มีการเปรียบเทียบมากกว่า 30 โมเดลจากหลายค่าย
การใช้โมเดลที่มี output token แพงอาจทำให้ต้นทุนพุ่งสูงโดยไม่รู้ตัว
หากไม่จำกัดความยาวคำตอบหรือใช้ prompt ที่ไม่กระชับ อาจเสียเงินมากเกินจำเป็น
ควรตั้งค่า max_tokens และ temperature ให้เหมาะสม
การเปรียบเทียบราคาโดยไม่ดูคุณภาพอาจทำให้เลือกโมเดลไม่เหมาะกับงาน
โมเดลราคาถูกอาจไม่เหมาะกับงาน reasoning หรือการเขียนเชิงลึก
ควรพิจารณาความสามารถของโมเดลควบคู่กับราคา
การเปลี่ยนแปลงราคาบ่อยครั้งอาจทำให้ข้อมูลล้าสมัยเร็ว
ควรตรวจสอบราคาจากเว็บไซต์ทางการก่อนใช้งานจริง
การใช้ข้อมูลเก่าอาจทำให้คำนวณต้นทุนผิดพลาด
การใช้โมเดลที่มี context window ใหญ่เกินความจำเป็นอาจสิ้นเปลือง
โมเดลที่รองรับ context 1M tokens มักมีราคาสูง
หากงานไม่ต้องการ context ยาว ควรเลือกโมเดลที่เล็กลง
https://pricepertoken.com/
ลองจินตนาการว่า AI ที่คุณใช้ตอบคำถามหรือเขียนบทความนั้น คิดค่าบริการเป็น “จำนวนคำ” ที่มันอ่านและเขียนออกมา—หรือที่เรียกว่า “token” ซึ่งแต่ละ token คือเศษคำประมาณ 3–4 ตัวอักษร
ในปี 2025 นี้ ตลาด LLM API แข่งขันกันดุเดือด ผู้ให้บริการอย่าง OpenAI, Google, Anthropic และ xAI ต่างออกโมเดลใหม่พร้อมราคาที่หลากหลาย ตั้งแต่ราคาถูกสุดเพียง $0.07 ต่อ 1 ล้าน token ไปจนถึง $600 ต่อ 1 ล้าน token สำหรับโมเดลระดับสูงสุด!
สิ่งที่น่าสนใจคือ “ราคาสำหรับการตอบ” (output token) มักแพงกว่าการถาม (input token) ถึง 3–5 เท่า ทำให้การออกแบบ prompt ที่กระชับและฉลาดกลายเป็นกลยุทธ์สำคัญในการลดต้นทุน
โมเดลราคาถูกที่สุดในตลาดตอนนี้ ได้แก่ Google Gemini 2.0 Flash-Lite และ OpenAI GPT-4.1-nano
ราคา input token อยู่ที่ $0.07–$0.10 ต่อ 1 ล้าน token
ราคา output token อยู่ที่ $0.30–$0.40 ต่อ 1 ล้าน token
โมเดลระดับกลางที่คุ้มค่า เช่น GPT-4o-mini และ Claude Haiku 3
ราคา input token อยู่ที่ $0.15–$0.25
ราคา output token อยู่ที่ $0.60–$1.25
โมเดลระดับสูง เช่น Claude Opus 4 และ GPT-o1-pro มีราคาสูงมาก
Claude Opus 4: $15 (input) / $75 (output)
GPT-o1-pro: $150 (input) / $600 (output)
แนวโน้มการตั้งราคาคือการแยก input กับ output token อย่างชัดเจน
output token แพงกว่า input token หลายเท่า
ส่งเสริมการใช้เทคนิค RAG (Retrieval-Augmented Generation) เพื่อประหยัด
ข้อมูลอัปเดตล่าสุดเมื่อวันที่ 27 กรกฎาคม 2025
แหล่งข้อมูลมาจากเว็บไซต์ทางการของผู้ให้บริการแต่ละราย
มีการเปรียบเทียบมากกว่า 30 โมเดลจากหลายค่าย
การใช้โมเดลที่มี output token แพงอาจทำให้ต้นทุนพุ่งสูงโดยไม่รู้ตัว
หากไม่จำกัดความยาวคำตอบหรือใช้ prompt ที่ไม่กระชับ อาจเสียเงินมากเกินจำเป็น
ควรตั้งค่า max_tokens และ temperature ให้เหมาะสม
การเปรียบเทียบราคาโดยไม่ดูคุณภาพอาจทำให้เลือกโมเดลไม่เหมาะกับงาน
โมเดลราคาถูกอาจไม่เหมาะกับงาน reasoning หรือการเขียนเชิงลึก
ควรพิจารณาความสามารถของโมเดลควบคู่กับราคา
การเปลี่ยนแปลงราคาบ่อยครั้งอาจทำให้ข้อมูลล้าสมัยเร็ว
ควรตรวจสอบราคาจากเว็บไซต์ทางการก่อนใช้งานจริง
การใช้ข้อมูลเก่าอาจทำให้คำนวณต้นทุนผิดพลาด
การใช้โมเดลที่มี context window ใหญ่เกินความจำเป็นอาจสิ้นเปลือง
โมเดลที่รองรับ context 1M tokens มักมีราคาสูง
หากงานไม่ต้องการ context ยาว ควรเลือกโมเดลที่เล็กลง
https://pricepertoken.com/
💸 เรื่องเล่าจากโลก AI: “ราคาคำตอบ” ที่คุณอาจไม่เคยคิด
ลองจินตนาการว่า AI ที่คุณใช้ตอบคำถามหรือเขียนบทความนั้น คิดค่าบริการเป็น “จำนวนคำ” ที่มันอ่านและเขียนออกมา—หรือที่เรียกว่า “token” ซึ่งแต่ละ token คือเศษคำประมาณ 3–4 ตัวอักษร
ในปี 2025 นี้ ตลาด LLM API แข่งขันกันดุเดือด ผู้ให้บริการอย่าง OpenAI, Google, Anthropic และ xAI ต่างออกโมเดลใหม่พร้อมราคาที่หลากหลาย ตั้งแต่ราคาถูกสุดเพียง $0.07 ต่อ 1 ล้าน token ไปจนถึง $600 ต่อ 1 ล้าน token สำหรับโมเดลระดับสูงสุด!
สิ่งที่น่าสนใจคือ “ราคาสำหรับการตอบ” (output token) มักแพงกว่าการถาม (input token) ถึง 3–5 เท่า ทำให้การออกแบบ prompt ที่กระชับและฉลาดกลายเป็นกลยุทธ์สำคัญในการลดต้นทุน
✅ โมเดลราคาถูกที่สุดในตลาดตอนนี้ ได้แก่ Google Gemini 2.0 Flash-Lite และ OpenAI GPT-4.1-nano
➡️ ราคา input token อยู่ที่ $0.07–$0.10 ต่อ 1 ล้าน token
➡️ ราคา output token อยู่ที่ $0.30–$0.40 ต่อ 1 ล้าน token
✅ โมเดลระดับกลางที่คุ้มค่า เช่น GPT-4o-mini และ Claude Haiku 3
➡️ ราคา input token อยู่ที่ $0.15–$0.25
➡️ ราคา output token อยู่ที่ $0.60–$1.25
✅ โมเดลระดับสูง เช่น Claude Opus 4 และ GPT-o1-pro มีราคาสูงมาก
➡️ Claude Opus 4: $15 (input) / $75 (output)
➡️ GPT-o1-pro: $150 (input) / $600 (output)
✅ แนวโน้มการตั้งราคาคือการแยก input กับ output token อย่างชัดเจน
➡️ output token แพงกว่า input token หลายเท่า
➡️ ส่งเสริมการใช้เทคนิค RAG (Retrieval-Augmented Generation) เพื่อประหยัด
✅ ข้อมูลอัปเดตล่าสุดเมื่อวันที่ 27 กรกฎาคม 2025
➡️ แหล่งข้อมูลมาจากเว็บไซต์ทางการของผู้ให้บริการแต่ละราย
➡️ มีการเปรียบเทียบมากกว่า 30 โมเดลจากหลายค่าย
‼️ การใช้โมเดลที่มี output token แพงอาจทำให้ต้นทุนพุ่งสูงโดยไม่รู้ตัว
⛔ หากไม่จำกัดความยาวคำตอบหรือใช้ prompt ที่ไม่กระชับ อาจเสียเงินมากเกินจำเป็น
⛔ ควรตั้งค่า max_tokens และ temperature ให้เหมาะสม
‼️ การเปรียบเทียบราคาโดยไม่ดูคุณภาพอาจทำให้เลือกโมเดลไม่เหมาะกับงาน
⛔ โมเดลราคาถูกอาจไม่เหมาะกับงาน reasoning หรือการเขียนเชิงลึก
⛔ ควรพิจารณาความสามารถของโมเดลควบคู่กับราคา
‼️ การเปลี่ยนแปลงราคาบ่อยครั้งอาจทำให้ข้อมูลล้าสมัยเร็ว
⛔ ควรตรวจสอบราคาจากเว็บไซต์ทางการก่อนใช้งานจริง
⛔ การใช้ข้อมูลเก่าอาจทำให้คำนวณต้นทุนผิดพลาด
‼️ การใช้โมเดลที่มี context window ใหญ่เกินความจำเป็นอาจสิ้นเปลือง
⛔ โมเดลที่รองรับ context 1M tokens มักมีราคาสูง
⛔ หากงานไม่ต้องการ context ยาว ควรเลือกโมเดลที่เล็กลง
https://pricepertoken.com/
0 ความคิดเห็น
0 การแบ่งปัน
218 มุมมอง
0 รีวิว